침해사고에 대한 충분한 근거 자료를 확보하고 원인에 대한 분석이 완료되었다면 원인과 근거 자료를 기반으로 향후 대응 방안을 수립한다. 수립된 대응 방안에 필요한 할 일(액션 아이템)을 가능한 상세하게 구분하여 침해사고가 재발되지 않도록 방안을 제시한다.
종합적인 분석 결과를 기반으로 조직의 의사결정권자는 필요한 조치를 수행할 리소스를 확보하고 정해진 기한에 따라 이행 사항을 실행 한다.
분석 결과 보고
보고 대상을 고려해 적절한 단어와 표현 방법을 사용해 핵심 사항을 전달하는 것이 보고서 작성의 기본이다.
그렇다면 보안 위협 분석 보고서의 작성 시 가장 중요한 부분은 무엇일까? 이슈에 대한 핵심과 적절한 대응 전략이 포함되는 것은 물론 적정한 시기에 보고서가 전달 되는 것도 중요하다. 모든 주요 이슈에 대한 의사 결정이 끝나고 난 후에는 아무리 완벽한 보고서도 그 빛을 잃는다.
상황정의나 침해단계 정의 내용을 전달하여 상황 요약 전달
대응에 필요한 충분한 정보가 제공되었는가?
보고서 제공시기와 횟수가 적절한가?
보고서를 구성하는 항목은 다음과 같다. 기본적인 핵심 정보를 전달하기 위해 공통 항목에 대해 조직의 내부 정책에 따라 유형을 분류하고 보고서 작성 시 판단 기준에 따라 해당 항목을 기입한다.
위협 분석 방법론은 쉽게 얘기해서 어떻게 분석을 할지 정의 하는 것이다. 가장 대표적인 분석 방법론으로 블랙리스트 방식과 화이트리스트 방식이 있다. 먼저 블랙리스트 방식은 기존에 위험하다고 알려져 있는 키워드나 이벤트를 중심으로 수집된 정보를 분석하는 방법이다. 방대한 정보에서 정해진 정보만을 검색하기 때문에 상대적으로 분석 소요 시간이 짧다. 하지만 알려진 정보를 가지고 검색하기 때문에 언노운[1] 공격은 찾아내기 어렵다. 반대로 화이트 리스트 방식은 확인된 정상 범주의 정보를 제외한 모든 정보를 분석하는 방법이다. 블랙리스트 방식에 비해 분석할 양도 많고 분석 시간도 많이 소요 된다. 하지만 언노운 공격도 분석이 가능한 방법이다.
분석한 이벤트가 왜 공격인가에 대해서 정의하기 위해서는 먼저 왜 공격이 아닌지 알고 있어야 한다. 다시 말해 정상 통신이나 정상 행위가 무엇인지 알고 있어야 한다. 보안을 입문하는 사람들에게 기본을 강조하는 이유이기도 하다. 애플리케이션이나 네트워크 통신이 어떻게 이뤄지는지 알고 있다면 정상 통신과 비정상 통신을 구분할 수 있다.
텔넷이나 SSH, 원격데스크탑 연결 등 사용자 대화 방식(user interaction) 기반 통신은 해킹에 자주 사용되는 통신 방식이다.
다음 표는 침입탐지시스템에서 추출한 침입탐지 이벤트에 대한 정보를 요약한 표다.
탐지항목
탐지정보
이벤트 수집 기간
3개월
탐지 시그니처 이름
TCP_Invalid_SACK
출발지 IP
10.0.0.1
출발지 포트
랜덤
도착지 IP
랜덤
도착지 포트
랜덤
총합
1441 건
표 IDS 이벤트 분석 정보 요약
TCP_Invalid_SACK 라는 침입탐지시스템 시그니처는 비정상 SYN 패킷과 ACK 패킷에 의해 발생된다. 일반적으로 TCP 통신은 프로토콜에 정해진 방법으로 필요한 통신 패킷을 주고 받는다. 하지만 통신에 사용되는 프로그램이나 네트워크 특성에 따라 정해진 프로토콜과 다른 방식으로 통신하는 현상이 발생한다. TCP_Invalid_SACK 시그니처는 이러한 현상을 기록한다.
이러한 이유로 공격자가 비표준 방식의 프로그램을 사용할 때도 통신 내역이 탐지된다. 물론 탐지된 정보에는 공격자의 통신만 기록되진 않는다. 탐지된 1441건의 이벤트에 공격자가 통신한 횟수는 소수일 것이다. 보안 분석가는 이벤트 분석을 통해 소수의 공격 탐지 건수를 찾아야 한다.
정상 통신과 비정상 통신을 구분하기 위해 먼저 전체 통신 내역을 하나의 큰 그림으로 정리할 필요가 있다. 각각의 날짜에 어떤 포트들이 사용됐고, 사용된 횟수를 누적한 정보를 표로 정리할 수 있다.
포트 통신 통계
표를 작성하는 과정은 유튜브 영상을 참고 할 수 있다.
이제 추출한 로그에서 어떤 공격이 발생했는지 같이 분석해 보자.
정상 통신과 비정상 통신의 차이가 무엇 일까?
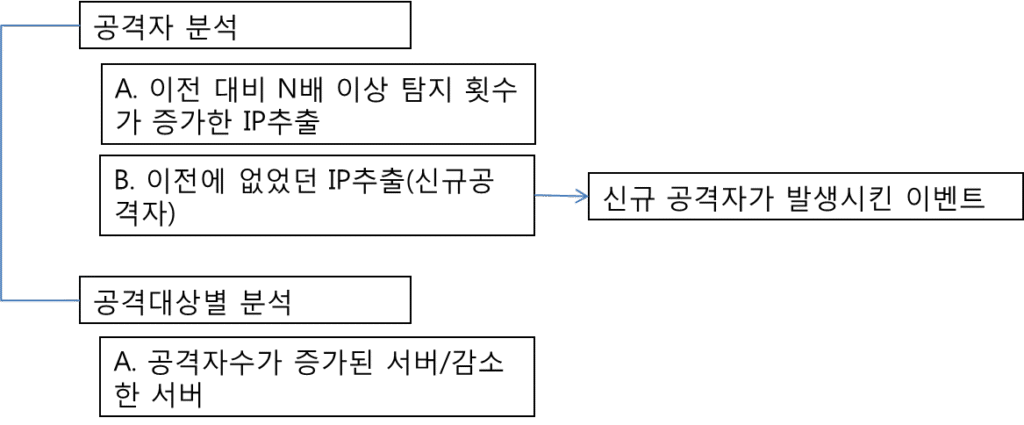
그 차이를 구분하기 위해서는 여러분들은 정상 통신과 비정상 통신의 기준을 만들어야 한다. 정상과 비정상 통신의 차이를 접속횟수라는 기준으로 가정해 보자. 좀더 구체적으로 이전보다 갑자기 접속횟수가 4배 이상 증가된 경우 비정상 통신으로 가정해 보자.
앞서 표로 만들었던 통신 포트 통계를 다시 살펴보면 이상한 현상이 눈에 들어 올 것이다.
포트 통계 표에 22, 1501, 8002번 포트의 접속 횟수가 비정상적으로 증가 하거나 감소한 것으로 알 수 있다. 여기까지는 분석하는 사람의 가설에 의한 의심이고 정확한 분석을 위해서는 상세한 내역을 보고 판단하자.
각각의 통신 내역을 상세하게 살펴보자.
먼저 22번 포트의 통신 내역을 살펴보자. 의심스러운 통신 내용 중 어느 것을 먼저 볼지는 분석하는 사람들의 의도에 따라 적절히 판단하자.
이번 경우에는 사용자가 시스템에 명령(user interaction)을 주고 받을 수 있는 SSH통신이 위험도가 높기 때문에 SSH접근 내역에 대한 분석을 먼저 진행 했다.
엑셀로 추출한 로그를 분석할 때는 원본 정보가 변경되는 것을 막기 위해 파일을 복사해서 작업하거나 파일에 새로운 시트를 추가하고 복사한 정보를 가공하자.
분석할 정보가 22번 포트 통신에 대한 내용이기 때문에 나머지 통신에 대해서는 일단 제외 처리한다. 엑셀의 필터 메뉴를 이용해서 22번을 제외하고 모든 숨긴 후 탐지로그를 복사한다.
그림 SSH 탐지 로그 분석
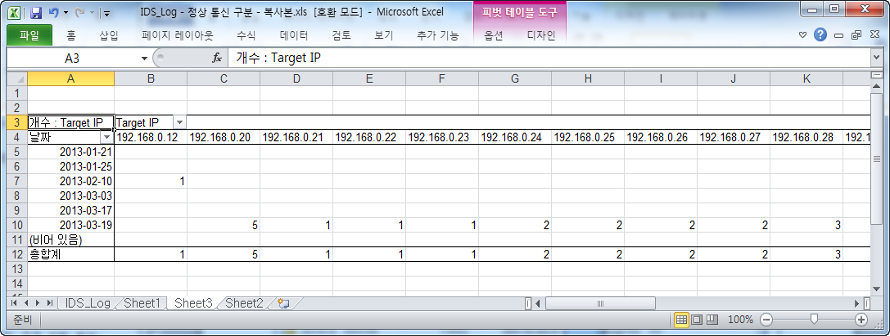
도착지 포트(Target Port) 22번 포트에 대해서만 별도로 추출했기 때문에 이제 날짜별로 공격대상이 어떻게 이뤄지는지 살펴 보자.
날짜와 도착지 IP 컬럼만 선택해서 새로운 시트에 복사하고, 피벗 테이블을 작성한다.
그림 공격대상 분석
22번 포트로 통신한 도착지 IP에 대한 현황 정리가 완료 되었다. 하나의 출발지 IP에서 여러 도착지 IP에 접근을 했고, 접근을 시도했던 날짜도 19일에 집중되어 있다.
19일 날짜에 접속된 통신 내역을 다시 한번 상세하게 살펴본다.
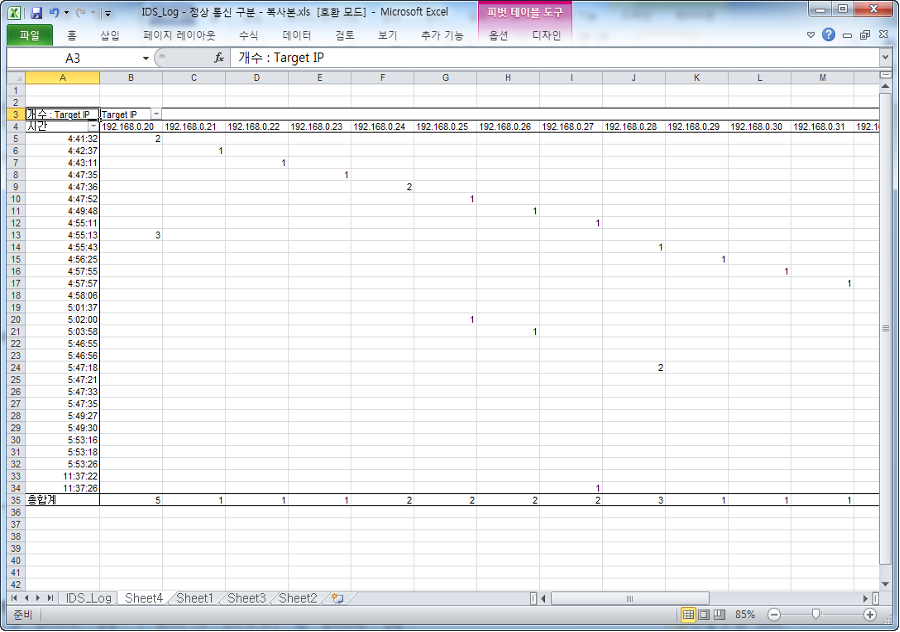
19일에 발생된 침입탐지 로그만 선택해서 새로운 시트에 복사 한다. 복사한 로그를 다시 한번 피벗 테이블을 이용해서 시간대별 통신한 도착지 IP를 정리한다.
피벗 테이블을 만드는 방법은 다음 순서로 진행 한다.
피벗 테이블을 생성하고 행 필드에 시간을 끌어서 이동
열 필드에 Target IP를 끌어서 이동
값 필드에 Target IP를 끌어서 이동
그림 시간대별 통신 분석 1그림 시간대별 통신 분석 2
완성된 테이블을 살펴보자. 새벽 4시를 시작으로 서로 다른 시스템에 1~2회씩 통신이 약 30초에서 1분 간격으로 이뤄졌다.
이렇게 통신이 발생될 수 있는 유형은 대표적으로 다음 2가지 형태가 있다.
예약된 작업에 의해 정기 점검
스캐닝 프로그램에 의한 네트워크 포트 스캔 시도
예약된 작업의 경우는 매주 지정 요일이나 매달 지정날짜에 발생하기 때문에 해당되지 않는다. 스캐닝에 의한 접근 시도일 가능 성이 높다. 내부 시스템간에 스캐닝이 발생했다는 것은 출발지 IP가 공격자에 장악됐을 가능성이 매우 높다. 공격에 사용된 내부 시스템을 찾아낸 것이다.
공격자는 백도어가 설치된 내부 시스템(10.0.0.1)을 경유해 2차 공격을 수행했다.
사전에 수집했던 로그인 정보를 이용해 단순 스캔이 아닌 시스템 로그인에 성공했고, 접속한 시스템에 공격 스크립트를 실행했다.
공격자는 공격 스크립트를 통해 하드디스크에 ‘PRINCIPES’ 문자열로 채워서 디스크를 못쓰게 만드는 명령을 실행했다.
많은 탐지 로그 중에서 이전 대비 급격한 통신 횟수의 변화가 생긴 로그를 의심 행위로 간주했다. 짧은 시간(수초 간격)에 다수의 시스템에 접속한 시스템 로그를 추출했고, 상세 분석을 통해 공격자에 의한 시스템 피해를 확인했다.
특정 문구가 아닌 횟수 변화를 이용해 공격을 구분하는 방법이 임계치 기반의 분석 방법이다.
임계치 기반의 상관 분석을 위해서는 기본 프로파일 정보가 필요하다. 프로파일을 정의 하는 방법은 정상 상황을 정의하고 이에 벗어나는 상황을 분리한다.
앞서 살펴본 예제에서는 정상 상황의 통신은 꾸준하게 통신이 발생한다라는 프로파일을 정의 한 것이다. 이를 기준으로 꾸준하기 않은, 즉 “접속횟수가 이전보다 N배 이상 차이가 나는 것”을 의심스런 통신으로 정의 했다.
프로파일 정의에 사용될 수 있는 정보
매시간 외부와 주고 받는 최대 트래픽 수치
매일 외부와 주고 받는 최대 트래픽 수치
비업무 시간 외부와 통신하는 내부 시스템 수
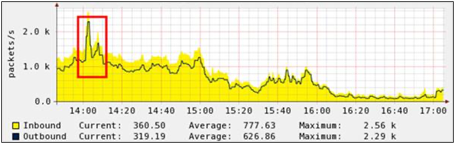
외부로 중요한 데이터가 유출되었다고 가정해 보자. 해당 데이터는 일반적으로 주고 받는 파일보다 매우 큰 파일이라고 했을 때, 아래 그래프와 같이 평상 시 트래픽을 벗어나 급증한 그래프는 해당 가설을 입증하는 데이터가 될 수 있다.
그림 임계치 기반 분석
통계학적인 관점에서 접근하는 방법으로 침입탐지시스템 로그를 이용해 다음과 같이 이상 통신에 대한 기준을 정의할 수 있다.
공격자/피해자 분석
시스템에 이상이 발생하거나 악성코드가 설치된 시점을 기준으로 관련 이벤트를 검색하고 검색한 이벤트를 이용해 공격 대상을 추출한다. 특정 사건이 발생된 시간이 확인되면 이전에 발생한 이벤트를 분석한다. 침해사고가 발생되면 공격자에 대해 역추적하는 과정이다.
최초 공격을 위해 사전 공격 시점이 언제인지 분석을 하고, 이 후 취약점을 이용해 공격이 성공한 시점을 찾는다.
예제를 살펴보자. 침입탐지시스템 로그에서 공격을 시도한 IP와 공격자가 사용한 취약점을 분석하는 과정이다.
피해를 받은 대상 시스템을 구분하기 위해 침입탐지시스템 로그에서 공격 대상별로 이벤트 발생 시간을 목록화 한다. 단순 스캔 시도한 탐지 로그를 제외하고 대상 시스템을 목록화 한다.
다음 표처럼 대상 시스템 목록과 각각의 대상 시스템이 8월 한달 동안 공격 받았던 취약점 종류(탐지수), 공격자 IP 종류를 목록화 한다.
대상시스템
탐지수
공격자IP 종류
최초 이벤트 발생 시간
최종 이벤트 발생 시간
타켓시스템1
9994
4550
2015-08-01 0:00
2015-08-30 15:00
타켓시스템2
6519
2433
2015-08-01 0:00
2015-08-30 15:00
타켓시스템3
75
1
2015-08-01 0:00
2015-08-30 14:00
타켓시스템4
74
1
2015-08-01 0:00
2015-08-30 14:00
타켓시스템5
9878
1495
2015-08-01 0:00
2015-08-30 15:00
타켓시스템8
128426
8277
2015-08-01 0:00
2015-08-30 15:00
타켓시스템6
79
12
2015-08-02 0:00
2015-08-29 0:00
타켓시스템9
107
2
2015-08-03 13:00
2015-08-27 15:00
타켓시스템7
1
1
2015-08-05 15:00
2015-08-05 15:00
타켓시스템12
7
1
2015-08-06 0:00
2015-08-27 23:00
타켓시스템10
16
4
2015-08-06 16:00
2015-08-29 19:00
타켓시스템11
9
1
2015-08-07 19:00
2015-08-25 10:00
표 공격 대상 시스템 목록
반대로 공격을 시도했던 공격자 IP를 목록화 하고, 침해사고 원인을 역추적하는 방법도 있다.
앞서 보안 위협 분석을 위해 어떠한 정보가 필요한지와 필요한 정보를 수집하는 방법을 살펴 봤다. 이번 장에서는 수집한 정보를 분석해 위협이 되는 이벤트와 그렇지 않은 이벤트를 구분하는 방법을 살펴 볼 것이다.
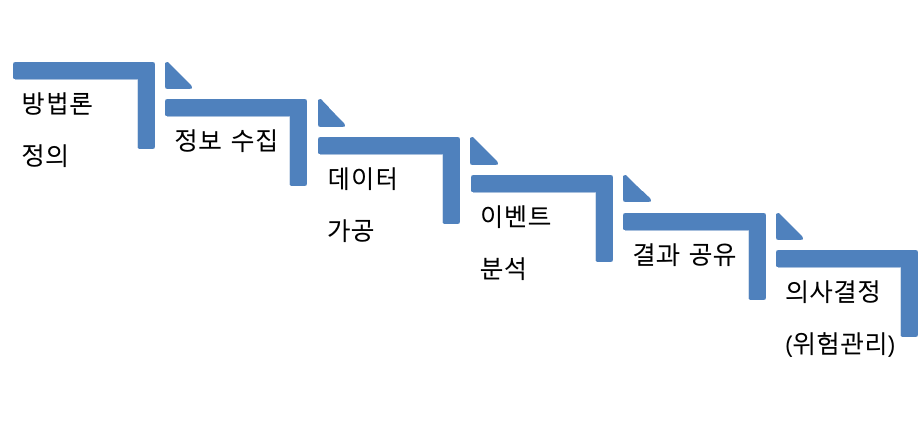
일반적으로 보안분석가가 보안 위협을 구분하는 과정은 다음과 같다. 보안 위협이나 피해 형태에 따라 필요한 방법론을 정의 하고, 방법론에 적합한 증거를 수집한다. 수집한 증거는 가공 과정을 거쳐 분석에 필요한 정보를 찾아낸다. 분석된 결과는 업무프로세스에 따라 보고 과정을 거쳐 최종적으로 의사 결정자에 의해 결론을 정의 한다.
분석에 사용될 방법론은 위협을 구분하고, 식별하기 위해 어떤 방법을 사용할지 정의 하는 것이다. 공격과 관련된 알려진 특징을 이용할 수도 있고, 수집된 정보를 가공해 통계적인 수치를 이용해 위협을 식별할 수도 있다.
필요한 분석 방법에 따라 수집되는 정보도 차이가 난다. 공격의 특징을 이용해 위협을 분석하기 위해서는 시그니처 기반의 탐지 정보가 필요하지만 통계정보를 이용하기 위해서는 수치화된 정보가 필요 하다.
필요한 정보가 수집이 완료되면 데이터를 가공해서 불필요하거나 분석 우선 순위가 낮은 데이터를 제외한다. 처음부터 끝까지 모든 정보를 분석하면 좋겠지만 제한된 시간과 자원을 가지고 분석하기 때문에 효율적으로 작업 해야 한다.
데이터가공까지 완료되면 위협을 식별하고 식별된 위협 결과에 따라 피해범위와 대응방안을 수립한다. 분석가에게 중요한 역량은 IT보안사고와 연관된 원인을 정확히 규명하고 사고로 인한 피해 범위를 정확히 파악하는 것이다. 분석가의 결론으로 기업이나 조직에 미치는 피해 범위를 정의한다.
분석된 내용은 보고서로 작성해서 대응방안과 함께 의사결정자에게 제공한다. 분석 결과는 의사 결정에 필요한 필수 정보로 사용된다.
해커에 의해 시스템을 공격 받게 되면 그 흔적이 남게 된다. 운영체제와 네트워크 트래픽에 남아 있는 공격자의 흔적이 무엇인지 살펴 보자. 공격 흔적을 찾기 위해서 특정 툴이나, 내장 명령, 스크립트 등을 이용해 시스템에서 정보를 추출 할 것이다. 정보 추출을 위해 필요한 옵션과 분석 시 도움되는 정보들을 살펴보자.
운영체제 메모리에 올라와 있는 정보나 네트워크 통신 정보들은 시간이 지나면 사라지는 정보다. 휘발성 정보가 무엇이고, 어떤 흔적이 남아 있는지 살펴보자.
세션 정보 수집
시스템에 남아 있는 정보 중 네트워크 통신 정보는 연결이 종료되면 사라진다. 키로깅 프로그램이나 백도어 프로그램은 피해 시스템에서 수집한 정보를 전송 하기 위해 외부와 통신을 해야 한다. 외부와 통신하기 위해 피해 시스템에 설치된 악의적인 프로그램은 프로세스를 생성한다. 백도어가 사용하는 프로세스를 확인하면 사용되는 파일과 통신 대상 정보를 알아 낼 수 있다.
정보를 수집할 때는 시스템의 내장 명령이 조작되었을 가능성이 있기 때문에 점검에 사용할 실행 프로그램을 따로 준비하는 게 좋다.
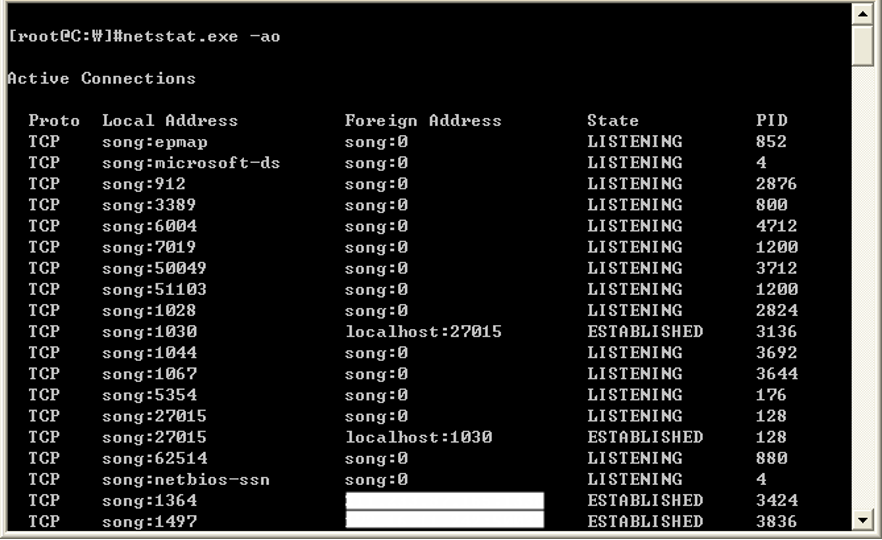
시스템간에 연결된 통신을 세션이라고 부른다. 이 세션 정보를 수집하기 위해 ‘netstat.exe’ 명령을 이용한다. 명령 옵션은 다음과 같다.
-a: 모든 연결 및 수신 대기 포트를 표시합니다. -o: 각 연결의 소유자 프로세스 ID를 표시합니다. -n 주소 및 포트 번호를 숫자 형식으로 표시합니다.
‘ao’ 옵션과 함께 명령을 실행 시키면 다음과 같은 결과 화면이 출력 된다. 현재 시스템에서 연결된 모든 세션 정보가 화면에 출력된다.
그림 세션별 PID
확인된 전체 세션 목록을 점검하여 비정상 세션이나 사용하지 않는 세션을 추출하고, 해당되는 PID(프로세스ID)를 통해 의심되는 프로세스를 점검한다. 이 경우 순간적으로 통신을 맺고 바로 세션을 끊는 경우 확인이 어려울 수 있다.
일부 악성코드는 히든프로세스로 시스템에서 대기 하고 있다 일정 주기나 특정 조건에 의해 세션을 연결하여 통신을 시도하고, 통신이 완료되면 세션을 종료한다.
일회성으로 연결을 맺고 금방 사라지는 세션을 점검하기 위해 실시간 모니터링 프로그램을 이용한다. 실시간 프로세스 모니터링은 TCPVIew , Seem(구Ekinx) 프로그램을 이용하여 확인 할 수 있다. 자동스크립트를 이용해 주기적으로 세션 정보를 저장해 일괄 확인하는 방법도 가능하다.
GUI 기반의 모티터링 프로그램을 실행시키면 다음 그림처럼 현재 시스템에 형성된 세션 정보를 출력한다. 세션 정보는 1초마다 자동 업데이트 된다. 업데이트 주기는 사용자가 메뉴에서 변경 할 수 있다.
그림 실시간 프로세스 모니터툴
실시간 모니터링 프로그램을 이용하면 외부로 연결을 시도하거나 내부로 연결을 시도하는 IP 정보를 확인하여 연관된 프로세스를 추출 할 수 있다. 윈도우처럼 리눅스도 동일하게 확인 가능하다. 필요에 따라 옵션항목을 조절해 사용 할 수 있다.
생성된 세션이 비정상이거나 시스템과 관련이 없을 경우 해당 프로세스에 대해 좀더 자세히 점검하고, 실제로 프로세스가 사용중인 파일에 대해 점검한다. 다음으로 세션을 유발 시킨 실행 파일을 확인하는 방법을 살펴보자.
세션별 실행파일
윈도우 실행파일 별로 PID번호와 현재 연결 상태, Local&Remote IP, Port정보를 점검 한다. 프로세스정보와 함께 분석한다. 악성 코드에 의한 연결 인지 정상 통신인지 확인한다. 점검은 윈도우 내장 명령이 아닌 별도의 무료 프로그램을 이용해 점검 할 수 있다.
tcpvcon을 다운받아 윈도우 명령 창에서 다음과 같이 실행 한다.
tcpvcon -n /accepteula
프로그램을 실행시키면 아래처럼 실행 파일별 PID정보와 연결 상태 및 상세 정보를 확인 할 수 있다.
세션 정보를 수집하는 방법을 살펴 봤다. 이번에는 여러분이 수집한 통신 연결 정보와 상세 실행 파일 정보를 활용하는 방법을 살펴 보자.
침해사고 분석에 어떻게 활용될 수 있는지 다음 사례를 같이 살펴 보자.
사례 분석
스팸 메일이 유포되었던 시스템을 분석했던 사례다.
침해가 발생한 시스템에서 특정 수신인을 대상으로 스팸 메일이 발송 되었다. 침해사고가 발생한 시스템이 중간 경유 시스템으로 이용되었는지 여부에 대한 분석을 진행 했다.
점검 대상 시스템은 윈도우 운영체제가 사용되고 있었다. 네트워크 방화벽에서 웹 서비스를 제외한 원격 접근은 불가능 하였다. 서비스 확인 시 웹 서비스 외 추가 서비스는 구동하지 않았다.
스팸 메일이 발송된 원인을 조사하기 위해 침입탐지시스템(Intrusion Detection System) 탐지 로그를 확인 하던 중 의심스런 통신 내역이 확인 되었다. 사용하지 않는 암호화 통신(SSL, Secure Sockets Layer)통신이 발생된 것이 확인 되었다. 상세 분석 시 점검 대상 시스템을 통해 해외 웹 메일 사이트에 접근 내역이 확인 됐다. HTTPS 통신을 통해 외부 웹 메일 서비스를 이용하였다.
프록시 설정이 의심되었고, 점검 결과 스팸 메일이 발송된 시스템을 거쳐 웹 메일 사이트에 접속하였고, 웹 서비스에서는 스팸 발송자를 해당 IP로 지목했던 것이다.
익명 웹 프록시 설정이 활성화 돼있을 경우 해당 시스템을 통해 타 사이트로 접근이 가능하게 되고, 이 경우 아래와 같은 구조로 중간(B Server)에서 중계 역할을 한다.
공격자 -> 중간 경유 서버(프록시서버) -> 웹 사이트
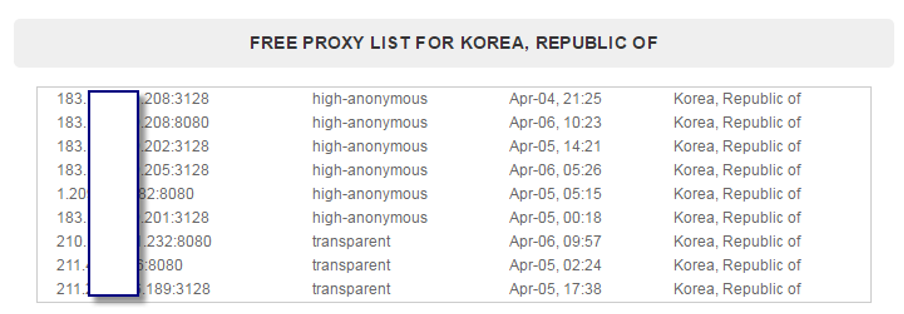
분석한 시스템은 중간 경우 서버에 해당 된다. 웹 사이트에는 공격자 IP가 아니라 중간 경유 서버 정보가 남는다. 참고로 익명 프록시 설정이 열리게 되면 해당 정보는 익명 프록시 서버 목록에 올라간다. 이 정보는 관리자가 의도하지 않은 피해를 유발할게 될 수 있다.
그림 익명 프록시 허용 서버 목록
스팸 발송 IP로 의심된 서버는 익명 프록시 허용으로 피해가 발생한 것이다. 자 그럼 프록시 서버로 이용된 사실을 어떻게 확인했는지 살펴 보자.
점검항목
분석 결과
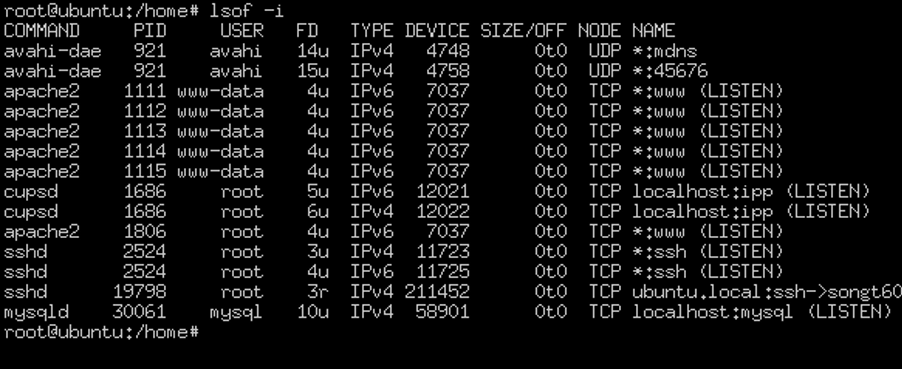
세션 정보
다수의 웹 서비스 세션이 확인80번 출발지 포트 아웃바운드 연결불특정 다수 사용자가 경유를 통해 타 사이트로 접근
취약 경로 분석
익명 프록시 접근 허용
로그점검
제공하지 않는 서비스 로그 확인경유로 인한 외부 서비스 URL 제공 로그
표 점검 요약
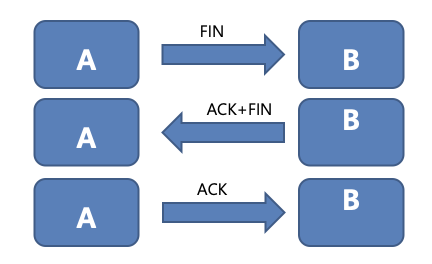
세션 분석 결과 다수의 아웃바운드 통신이 확인 됐다. 다수의 FIN_WAIT_2 상태가 확인 됐다.
FIN_WAIT_2 상태는 통신을 종료하는 과정에서 FIN 패킷을 전송하고 상대방에서 ACK를 수신하지 못해 기다리고 있는 상태를 의미 한다. 다음 그림에서 FIN을 보내고 두 번째 단계로 ACK와 FIN요청을 받아야 되는데 ACK 응답이 오지 않아 기다리고 있는 상태가 FIN_WAIT_2다.
일반적으로 웹 서버는 클라이언트에서 FIN 요청을 보내면 ACK 응답을 보낸다.
하지만 이 경우 웹 서버가 마치 클라이언트처럼 웹 서버에 FIN 요청을 보내고 또 다른 웹 서버의 응답을 기다리고 있었다(FIN_WAIT_2). 통신을 주고 받는 주체가 반대로 보였다. 이 정보를 기반으로 프록시 설정을 의심했다.
스노트 는 오픈 소스 기반의 네트워크 침입탐지/차단시스템 이다. 현재 필드에서 사용중인 대부분의 침입탐지/차단시스템의 엔진이 스노트를 기반으로 만들어져 있다.
Snort® is an open source network intrusion prevention and detection system (IDS/IPS) developed by Sourcefire. Combining the benefits of signature, protocol and anomaly-based inspection, Snort is the most widely deployed IDS/IPS technology worldwide. With millions of downloads and approximately 300,000 registered users, Snort has become the de facto standard for IPS.
스노트 공식 홈페이지에서 rule파일을 배포하는데 배포하는 룰 파일은 2가지 종류가 있다. 첫번째 모든 사용자가 사용할 수 있는 Community Ruleset이 있고, 유료 회원에게 제공되는 Sourcefire VRT Certified Rulesets이 있다. 유료 사용자에게 제공되는 룰 셋에 최신버전이 포함되어 있다.
The same Snort ruleset developed for our NGIPS customers, immediately upon release – 30 days faster than registered users
Priority response for false positives and rules
Snort Subscribers are encouraged to send false positives/negatives reports directly to Talos
For use in businesses, non-profit organizations, colleges and universities, government agencies, consultancies, etc. where Snort sensors are in use in a production or lab environment. This subscription type does not include license to redistribute the Snort Subscriber Rule Set except as described in section 2.1 of the Snort Subscriber Rule Set License.
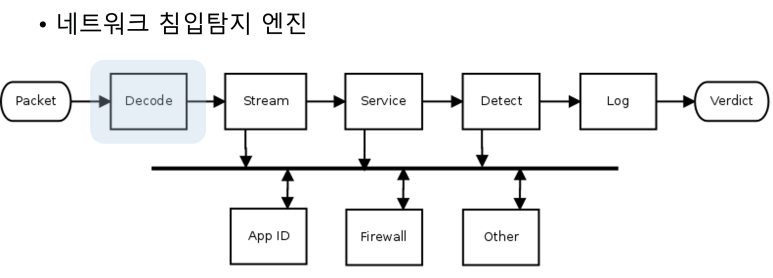
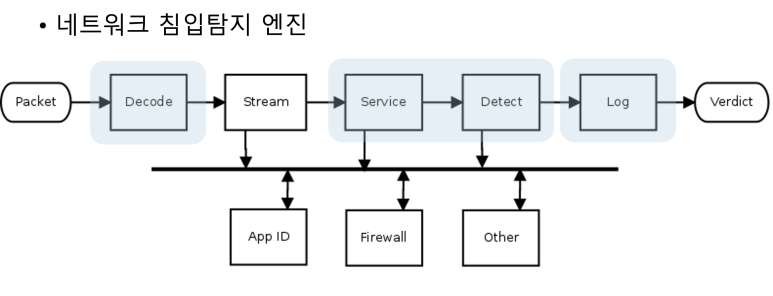
스노트 엔진 구조에 대해 살펴 보자. 스노트 엔진의 구조 분석을 통해 침입탐지시스템 구조를 이해할 수 있다. 공개용 침입탐지 시스템인 스노트의 탐지 매커니즘이 실제로 적용되는 것을 살펴 보고, 설정 및 시그니처에 대해 알아보자. 실제로 많은 수의 상업용 침입탐지/차단 시스템이 스노트 엔진을 사용하고 있기 때문에 실제 상업용 제품과 스노트 엔진 구조가 매우 유사하다고 생각하면 된다.
스노트의 구성은 크게 전처리기와 탐지엔진으로 구성된다. 전처리기는 스노트의 분석엔진에서 처리하기 전에 패킷에 대해 사전 검수를 진행 하는 역할을 한다. 전처리기의 종류는 프로토콜에 따라 다양하다.
탐지엔진은 시그니처를 기반으로 패턴 매치를 하는 방식으로 스노트 엔진 구동 시 관련 시그니처를 엔진에 올려 패킷을 분석한다. 시그니처로 사용되는 룰 파일은 제공되는 룰 파일을 사용할 수 있고, 사용자에 의해 직접 제작도 가능하다.
스노트 전처리기는 사용자에 의해 커스트마이징이 가능하고, 시그니처로 사용되는 룰파일 역시 커스트마이징 이나 직접 제작이 가능하다. 뒤 쪽에서 실제로 시그니처를 제작해보자. 먼저 시그니처 제작에 앞서 시그니처 작성 시 사용되는 변수 설정에 대해 살펴보고, 전처리기에 대해서도 살펴본 스노트 엔진의 설정과 관련된 내용은 Snort.conf 파일을 이용해 설정이 가능하다. 다음은 snort.conf 파일 일부다.
This file contains a sample snort configuration. You can take the following steps to create your own custom configuration: # 1) Set the variables for your network 2) Configure preprocessors 3) Configure output plugins 4) Add any runtime config directives 5) Customize your rule set
먼저 스노트 엔진에서 변수를 선언하는 방법을 살펴 보자.
변수(Variables)
변수는 3가지 종류의 변수 선언이 가능 하다. 일반적인 변수 선언에 사용되는 var, 포트 설정 시 사용하는 portvar, IPv6관련 설정 시 사용하는 ipvar 3가지가 있다.
var HOME_NET 10.1.1.0/24 var RULE_PATH ../rules (윈도우 시스템의 경우 절대 경로를 이용해야 합니다. ex c:\snort\rules) 단, var를 이용해 포트 변수를 선언할 때는 일반적으로 앞이나 뒤에 “PORT” 구문을 넣는다. var HTTP_PORT [80], var PORT_HTTP [80] var HTTP_PORT [80,8080] var RESERVED_PORT [1:1024] var MY_PORT [80,8080,1:1024] or var MY_PORT [80,8080,!1:1024] portvar MY_PORTS [22,80,1024:1050] ipvar MY_NET [192.168.1.0/24,10.1.1.0/24] Ipvar 변수의 경우 IPv6가 지원되는 경우에만 사용하고 지원되지 않을 경우 var사용 alert tcp any any -> $MY_NET $MY_PORTS (flags:S; msg:”SYN packet”;)
참고로 변수 선언은 상수를 이용해 정적으로 선언할 수 있고, 변수를 이용해 동적으로 사용할 수 있다. 다음 예제를 보자.
정적선언
var <desired_variable_name> <variable_value>
동적선언
var <desired_variable_name> $<variable:static_default_address>
var <desired_variable_name> $<variable:?Error: the variable was undefined>
정적선언은 변수에 상수값을 선언해 사용하고, 동적 선언은 고정된 값을 사용하지 않고, 유동적인 값을 이용한다.
IP리스트 조합에서 부정의 의미인 “!”(NOT) 기호를 사용 시 스노트 버전에 따라 해석에 차이가 있다. 2.7.X 이전 버전에서는 IP리스트 조합에서 각각의 객체는 OR 관계를 형성한다. 하지만 이후의 버전에서 해석되는 방식은 IP리스트 간에 “!”(NOT)이 포함되지 않을 경우에는 OR 관계를 형성하지만 “!”포함하는 객체는 OR 객체들과 AND관계를 형성한다. 예제를 살펴 보자.
var HOME_NET [10.1.1.0/24,192.168.1.0/24,!192.168.1.255]
위와 같이 선언되었을 때 HOME_NET 변수에 포함되는 IP리스트는 10.1.1.0/24 또는 192.168.1.0/24 이지만 192.168.1.255(브로드캐스트 IP) IP는 제외한다.
즉 ((10.1.1.0/24 or 192.168.1.0/24) and !192.168.1.255))로 해석된다. 참고로 IP변수에 “!any”와 같이 선언은 불가능하다.
IP리스트와 IP변수를 사용할 때 오류가 발생하지 않도록 주의해야 한다. 다음 예제는 변수 사용 시 발생할 수 있는 선언 오류다. 참고로 선언 오류가 포함된 변수를 이용해 시그니처를 제작하여 엔진 구동 시 시그니처를 사용하면 엔진에서 오류를 파악해 엔진에 올리는 것을 중지한다. 그리고 오류가 발생된 시그니처에 대해 데몬 실행 로그로 기록한다. 나중에 직접 시그니처를 제작할 때 오류가 발생되는 항목을 확인하는 방법으로 사용할 것이다.
정상 선언 ipvar EXAMPLE [1.1.1.1,2.2.2.0/24,![2.2.2.2,2.2.2.3]] alert tcp $EXAMPLE any -> any any (msg:”Example”; sid:1;) alert tcp [1.0.0.0/8,!1.1.1.0/24] any -> any any (msg:”Example”;sid:2;)
!any 오류 ipvar EXAMPLE any alert tcp !$EXAMPLE any -> any any (msg:”Example”;sid:3;)
논리 오류: 선언한 IP를 부정하여 선언할 수 없다. ipvar EXAMPLE [1.1.1.1,!1.1.1.1]
범위 오류: CIDR로 선언한 IP의 범위보다 더큰 범위로 !조건을 선언 할 수 없다. ipvar EXAMPLE [1.1.1.0/24,!1.1.0.0/16]
IP를 변수로 사용할 때와 마찬가지로 포트를 변수로 선언하는 방법도 3가지 방식이 있다.
단일 포트 선언: 80 포트 범위 지정: 1:1024 조합: [80,21:23]
선언 가능한 포트 범위는 0부터 65535 이다. IP변수와 마찬가지로 !any 사용은 불가능하다.
포트 변수의 경우 portvar 변수로 지정해 선언 할 수 있다. IP변수나 포트변수로 var 형식으로 선언은 이후에 지원되지 않을 수 있다. 포트로 선언하는 변수의 경우 네이밍 방식을 ‘_PORT’ 또는 ‘PORT_’ 형식으로 작성한다. 이번에 살펴볼 예제도 앞선 IP변수 선언과 마찬가지로 포트 선언 시 발생할 수 있는 선언 오류 예제이다. 변수 선언 시 오류가 발생하지 않도록 주의하자.
정상 선언 portvar EXAMPLE1 80 var EXAMPLE2_PORT [80:90] var PORT_EXAMPLE2 [1] portvar EXAMPLE3 any portvar EXAMPLE4 [!70:90] portvar EXAMPLE5 [80,91:95,100:200] alert tcp any $EXAMPLE1 -> any $EXAMPLE2_PORT (msg:”Example”; sid:1;) alert tcp any $PORT_EXAMPLE2 -> any any (msg:”Example”; sid:2;) alert tcp any 90 -> any [100:1000,9999:20000] (msg:”Example”; sid:3;)
!any 오류 portvar EXAMPLE5 !any var EXAMPLE5 !any
논리 오류 portvar EXAMPLE6 [80,!80]
포트 범위 오류: 지정된 포트 범위를 초과한 포트 번호를 선언할 수 없다. portvar EXAMPLE7 [65536]
사용 오류: IP 변수 위치에 포트 변수를 사용할 수 없다. alert tcp $EXAMPLE1 any -> any any (msg:”Example”; sid:5;)
I룰 헤더를 구성하는 항목을 표는 다음 같다.P와 포트를 변수 선언하는 방법과 오류가 발생되지 않도록 주의해야 할 부분에 대해 살펴 보았다. 이제 패킷에 대해 사전 검수를 하는 전처리기(Preprocessor)에 대해 살펴보자.
전처리기(Preprocessors)
앞서 전처리기의 역할이 패킷에 대한 사전 검수라고 했다. 이는 anomaly, 즉 비정상 트래픽의 경우 전처리기를 통해 처리 된다는 의미다. 비정상 헤더 구조의 패킷이나 비정상 트래픽을 전처리기에서는 구분 한다. 비정상 헤더 구조나 비정상 트래픽을 구분하기 위해서는 먼저 탐지한 패킷을 분해하는 과정이 필요하다. 이과정은 스노트 디코더를 통해 이뤄지고, 분해과정을 거쳐 전처리기에서는 패킷의 구조와 포함된 플래그 정보, 프로토콜 정보를 이용해 패킷이 갖춰야할 형식이나 프로토콜에 따른 패킷 구조를 해석한다.
탐지된 패킷은 헤더와 메타데이터, 페이로드로 구분 된다. 패킷은 스노트 엔진의 전처리기에서 TCP/IP 헤더 정보에 대해 검증을 거치게 된다. 비정상 헤더 구조를 가지고 있거나 조각난(fragmented)패킷은 조합하여 적절성을 검사 하게된다. 이 때 서비스에 따라 관련 프로토콜 정보에 대한 해석도 같이 진행된다. 일련의 전처리기의 패킷 검사가 진행되면, 이후 스노트 분석 엔진에서 시그니처를 이용해 페이로드에 포함된 데이터를 분석해 공격 여부를 결정 한다. 패킷을 침입탐지엔진에서 분석하기 전에 사전 검수 역할을 하는 전처리기를 스노트에서는 커스터마이징도 가능하다. 다음이 설정 파일에서 전처리기에 대해 옵션을 조절할 때 사용하는 설정 방법이다.
설정 방법에서 알 수 있듯이 전처리기에 따라 옵션을 이용해 설정을 할 수 있다. 스노트에서 제공하는 전처리기 종류는 다음과 같다.
전처리기종류
설명
frag2
Frag2 전처리기는 조각난 패킷을 재조합 한다. 단편화된 패킷을 이용한 공격을 탐지하기 위해 사용 된다. 기본 설정은 60초 timeout이며 조각난 패킷을 조합하기 위해 4MB까지 버퍼를 사용한다.
frag3
frag3 전처리기는 Target-based로 조각난 패킷을 재조합 한다.
Stream5
전송 데이터를 끊김 없이 지속적으로 처리하는 기술, 주로 동영상이나 오디오 데이터에서 모든 데이터를 수신하기 전에 전송과 동시에 데이터의 표현을 실행할 수 있다.
sfPortscan
소스파이어에서 개발한 모듈로 사전 공격 단계에 대해 탐지하는 모듈이다. 역할은 비정상 상황에 대해 탐지하는 것이다. 정상 통신이 아닌 정보를 수집하려 할 때는 사용하지 않는 포트 요청이나 IP요청이 자주 발생될 것이다. 예를 들어 정상 통신의 경우 오픈 또는 사용중인 포트나 IP로 통신이 많지, 사용하지 않는 IP또는 포트와 통신은 거의 드물다. 그래서 사용하지 않는 포트에 대해 요청이 많이 발생될 경우 비정상으로 인식을 하는 것이다. 다음은 몇 가지 비정상 상황에 대한 정의다.• 단일 소스에서 단일 목적지로 다수의 포트를 스캔, one->one portscans주요 공격 유형 TCP Portscan, UDP Portscan, IP Portscan• 조작된(Spoofed) 소스에서 단일 목적 시스템 스캔 TCP Decoy Portscan, UDP Decoy Portscan, IP Decoy Portscan• 다수의 소스에서 단일 목적 시스템 스캔, many->one portscansTCP Distributed Portscan, UDP Distributed Portscan, IP Distributed Portscan
RPC Decode
Remote Procedure Call(RPC)는 한 프로그램이 네트웍 상의 다른 컴퓨터에 위치하고 있는 프로그램에 서비스를 요청하는데 사용되는 프로토콜이다. RPC Decode 전처리기는 는 여러 개로 단편화된 RPC 레코드를 하나의 RPC레코드로 재조합 한다. 111, 32771 포트로 통신하는 패킷에 대해 처리 한다.
HTTP 통신에 대해 서버의 응답과 클라이언트의 요청을 스노트 분석 엔진에서 처리 하기 전에 normalize fields(정규화), decode를 담당한다. 추가로 각 필드에 대해서도 검색한다. 패킷 단위로 HTTP 필드를 처리하기 때문에 재조합 되지 않은 패킷을 처리하지 못한다. 재조합은 다른 모듈에 의지한다.• Decode 옵션ascii <yes|no>아스키 디코드 옵션utf 8 <yes|no>utf-8 디코드 옵션base36 <yes|no>base36 인코딩 문자의 디코드 옵션
SMTP
SMTP command와 data header, body를 구분한다. ‘RCPT TO:’, ‘MAIL FROM:’ 은 SMTP 명령어 이다. Preprocessor 옵션 조절 시 해당 항목은 RCPT, MAIL로 참조 된다.
데이터베이스에 저장한 스노트 탐지 내역을 쿼리하고 분석할 수 있도록 웹 인터페이스를 제공하는 공개용 분석툴이 몇 가지 있다. 이중 Basic Analysis and Security Engine(BASE) 프로젝트는 Kevin Johnson이 프로젝트를 이끌고 있고, Analysis Console for Intrusion Databases(ACID) 코드를 기초로한 프로젝트 이다. ACID는 PHP기반의 다양한 종류의 침입탐지시스템, 방화벽, 네트워크 모니터툴의 이벤트 데이터베이스를 분석하고 검색할 수 있는 엔진으로 Query-builder and search interface, Packet viewer (decoder), Alert management, Chart and statistics generation 기능을 제공 한다.
스노트 시그니처를 크게 2가지로 구분된다. 헤더 부분과 바디부분으로 나뉜다. 간단한 스노트 시그니처를 하나 살펴 보자. 예제로 살펴볼 시그니처는 HTTP_GET라는 이름의 스노트 시그니처다. 패킷의 데이터부분(페이로드)에서 GET이라는 문자열을 검색하여 탐지 하는 시그니처다.
alert tcp any any -> 10.10.10.0/24 80 (msg:”HTTP_GET”; content:”GET”)
해당 시그니처는 다음과 같이 헤더와 바디로 나눌 수 있다.
Header “alert tcp any any -> 10.10.10.0/24 80”Body “(msg:”HTTP_GET”; content:”GET”)”
헤더부분은 IP정보와 프로토콜 정보로 이뤄지고, 바디부분에 탐지 패턴과 규칙과 관련된 정보로 이뤄진다. 그럼 헤더부분과 바디부분에 어떤 항목이 있는지 자세히 살펴보자.
룰 헤더를 구성하는 항목을 표는 다음 같다.
항목
설명
Rule Actions
해당 Rule에 패킷이 탐지 되었을 때 취하는 액션으로 총 8가지로 대응 한다.
Protocols
TCP, UDP, ICMP, IP 등의 통신 프로토콜을 지정
IP Addresses
출발지, 도착지 IP 주소를 지정단일 IP와 CIDR block, IP 리스트로 지정할 수 있다.
Port Numbers
출발지, 도착지 Port 주소를 지정단일 Port와 범위, Port 리스트로 지정할 수 있다.
The Direction Operator
->, <>!주의, <- 방향 지시자는 없음
Activate/Dynamic Rules
룰 액션에서 activate, dynamic 지시에 따라 룰의 활성여부가 변동, 한 쌍으로 만든다.
표 룰 헤더 구문
헤더를 구성하는 각각의 항목은 실제 예제를 통해 살펴보자. 앞서 예제로 살펴본 스노트 시그니처의 헤더부분을 항목별로 구분해보자. 헤더의 정보를 해석해 보면 탐지된 패킷 중 프로토콜이 TCP인 패킷에 대해 검사를 하고, 출발지 IP와 포트는 별도로 지정하지 않았기 때문에 모든 출발지 IP와 포트가 해당된다. 도착지 IP와 포트는 10.10.10.0/24 대역에 80번 포트로 접속하는 패킷을 구분해서 분석 하겠다는의미가 된다. 이때 조건에 매치가 되면 스노트 엔진에서는 Alert이라는 액션을 취하겠다는 시그니처 설정을 의미한다.
액션
프로토콜
출발지
도착지
방향성
alert
tcp
any any
0.10.10.0/24 80
->
표 룰 헤더 예제
액션 항목은 Alert을 포함해 총 8가지의 액션 옵션이 있다. 모두 스노트 엔진에서 취하는 액션을 의미한다.
룰 액션 alert – 정해진 방식에 따라 Alert을 발생 시키로, 패킷을 기록한다. log – 패킷을 기록한다. pass – 탐지된 패킷을 무시한다. activate – Alert을 발생 시키고, 다이나믹룰을 활성화 시킨다. dynamic – 4번 액티브 룰에 의해 일정시간 동안 활성화되면 2번 로그 액션과 동일한 액션을 취한다. drop – iptable을 이용해 패킷을 드랍하고 패킷을 기록한다. reject – iptable을 이용해 패킷을 드랍하고 패킷을 기록하고, TCP reset 패킷을 출발지로전송하거나 ICMP 패킷의 경우 unreachable 메시지를 반송한다. sdrop – iptable을 이용해 패킷을 드랍하지만 로깅을 하지 않는다.
표 스노트 룰 액션
대부분의 시그니처의 액션이 Alert을 사용하고, activate 옵션과 dynamic 옵션은 잘 사용하지 않지만 사용은 다음과 같이 사용 가능 하다.
특정 BoF공격이 발생된 후에 다이나믹 룰이 활성화 되면 50개의 패킷을 로깅한다. 공격이 성공했을 때 이후에 발생된 행위에 대해 분석하기 위한 자료로 사용한다. activate tcp !$HOME_NET any -> $HOME_NET 143 (flags: PA; content: “|E8C0FFFFFF|/bin”; activates: 1; msg: “IMAP buffer overflow!”;) dynamic tcp !$HOME_NET any -> $HOME_NET 143 (activated_by: 1; count: 50;)
통신 프로토콜은 TCP, UDP, ICMP, IP 4개의 프로토콜을 지원한다.
출발지와 도착지에 대한 범위를 제한하기 위해 출발지/도착지 항목에 IP나, 포트정보를 입력하게 된다. 일반적으로 출발지 정보는 공격자의 IP를 알지 못하는 경우가 대부분이기 때문에 any로 지정하는 경우가 대부분이다. 다음은 IP/포트 정보를 선언하는 몇가지 예제로 참고하기 바란다.
gid (generator id)는 특정 룰이 발생했을 때 스노트 엔진의 어느 부분에서 룰을 발생 시켰는지 구분하기 위해 사용한다. gid 1-100은 전처리기와 디코더에서 사전에 할당되어 있다. 실제로 잘 사용하지 않는다.<형식>gid: <generator id>;
sid
Sid는 스노트 룰의 고유한 시그니처 ID다. 관련해서 사용 범위는 아래와 같다. • <100 Reserved for future use• 100-1,000,000 Rules included with the Snort distribution• >1,000,000 Used for local rules<형식>sid: <snort rules id>;
rev
Rule이 얼마나 많이 수정되었는지 표기 한다. “rev:6;”의 경우 6번 수정되었음을 의미 한다.<형식>rev: <revision integer>;
classtype
Classtype은 룰이 사전에 정의된 공격 형태에 대해 어떤 유형의 공격인지를 분류할 때 사용 한다. 룰에 대해 이벤트 유형을 분류한 것이다. 하지만 classtype을 사용하기 위해서는 snort.conf 파일에 classification 옵션이 설정되어야 한다.<형식>classtype: <class name>;
priority
룰의 위험도에 대해 숫자로 표기 한다. Priority 값은 중복 가능 한다.<형식>priority: <priority integer>;
metadata
metadata 항목은 룰에 key-value 형식으로 추가 정보를 작성할 때 사용 한다.
앞서 살펴본 옵션은 일반적인 시그니처 형식 정보를 나타내는 옵션이고, 이번에 살펴볼 옵션 항목은 페이로드에서 공격 패턴을 탐지하기 위해 사용되는 옵션이다.
항목
설명
content
문자열 기반의 패턴 매치의 스노트 룰에서 가장 핵심 옵션 항목으로 데이터 페이로그 값에서 원하는 문자열을 탐지 하기 위해 사용하는 옵션이 content 항목 이다.문자열 앞에 “!”을 사용할 경우 reverse개념으로 사용할 수 있다. ; \ “ 3개 캐릭터의 경우 구문 오류를 발생 시킬 수 있다. 반드시 이스케이 처리를 해야 한다.<형식>content: [!] “<content string>”;<example>alert tcp any any -> any 139 (content:”|5c 00|P|00|I|00|P|00|E|00 5c|”;)alert tcp any any -> any 80 (content:!”GET”;) GET문자를 포함하지 않는 TCP 80 트랙픽을 탐지 한다.
nocase
대소문자를 구분할 경우 ‘A’탐지 패턴은 ‘a’ 패킷을 탐지할 수 없게 된다. 대소문자를 구분하지 않게 하려면 nocase 옵션을 사용 한다.<형식>nocase;
rawbytes
탐지된 패킷 내용 데이터를 원시 데이터로 유지하여 비교한다. 앞서 살펴본 전처리기에선 일부 공격 패턴의 경우 엔진에서 정규화 시키기 때문에 패킷 원본과 비교가 필요 할 때 사용하는 옵션 이다.
depth
페이로드에서 찾은 내용의 범위를 지정 한다. 10으로 지정하면 페이로드 처음 시작에서 10바이트 안에서 패턴 검색을 한다.불필요한 부분을 건너뛸 수 있어 엔진을 효율적으로 사용할 수 있지만 이벤트 누락이 발생될 수 있으므로 사용 시 주의해야 하는 옵션 이다.depth옵션을 사용하기 위해서는 반드시 content 옵션이 depth옵션 앞에 와야 한다.<형식>depth: <number>;
offset
페이로드에서 찾을 내용의 시작 위치를 지정 한다. 10으로 지정하면 페이로드 처음 시작에서 10바이트 떨어진 곳에서부터 패턴 검색을 한다.불필요한 부분을 건너뛸수 있어 엔진을 효율적으로 사용할 수 있지만 이벤트 누락이 발생될 수 있으므로 사용 시 주의해야 하는 옵션 이다.offset옵션을 사용하기 위해서는 반드시 content옵션이 offset옵션 앞에 와야 한다.<형식>offset: <number>;<example>alert tcp any any -> any 80 (content: “cgi-bin/phf”; offset:4; depth:20;)
distance
룰 작성 시 이전 항목의 content와 매치되는 부분을 찾으면 distance에서 지정한 byte만큼 떨어진 지점부터 다음 content에 포함된 항목을 페이로드에서 찾는다.content옵션이 distance 옵션 앞에 와야 한다.<형식>distance: <byte count>;<example>alert tcp any any -> any any (content:”ABC”; content: “DEF”; distance:1;)페이로드에서 ABC문자열을 찾으면 distance 1바이트 만큼 떨어진 곳에서부터 DEF 문자열을 찾습니다. (offset의 확장개념)
within
룰 작성 시 이전 항목의 content와 매치되는 부분을 찾으면 매치된 부분부터 within에서 지정한 byte 내의 다음 content에 포함된 항목을 페이로드에서 찾는다.content옵션이 within옵션 앞에 와야 한다. (distance옵션과 같이 사용 된다.)<형식>within: <byte count>;<example>alert tcp any any -> any any (content:”ABC”; content: “EFG”; within:10;)
uricontent
Uricontent 옵션을 사용하면 URI필드에서 핵심적인 부분만을 검색하여 패턴문자열과 검색 한다. 핵심적인 부분의 의미는 NORMALIZED를 통해 일종의 정규화를 거쳐 공격 구문만을 추리는 형태이다.예를 들어 다음과 같이 directory traversal 공격 URI가 탐지 되었을 경우/scripts/..%c0%af../winnt/system32/cmd.exe?/c+ver정규화(normalized)를 거쳐 “/winnt/system32/cmd.exe?/c+ver” 구문을 추출하고, 해당 문자열과 공격패턴을 비교 한다.정규화를 사용하는 옵션이기 때문에 반대 옵션인 rawbytes와 같이 사용할 수 없다.<URI정규화 예제>/cgi-bin/aaaaaaaaaaaaaaaaaaaaaaaaaa/..%252fp%68f?/cgi-bin/phf?<형식>uricontent:[!]<content string>;
urilen
URI필드의 사이즈를 옵션으로 사용 한다. 공격 패턴 매치와 비교하고 추가로 탐지한 URI의 길이가 범위에 포함되는지 여부도 비교 한다. 비교 조건으로 크거나, 작거나, 같거나, 특정 범위 4가지 조건이 있다.urilen: 5urilen: < 5urilen: 5<>10<형식>urilen: int<>int;urilen: [<,>] <int>;<example>alert tcp any any -> any 80 (msg:”urilen”; content:”pattern”; urilen:5;)“pattern” 문자열이 포함될 경우 URI길이가 5바이트 인지 추가로 비교
isdataat
페이로드의 특정 위치에 데이터가 존재하는지 확인하거나 옵션을 이용해 이전 content 패턴과 매치 후 상대적인 위치에 대해 데이터가 존재하는지 확인 하는 옵션 이다.<형식>isdataat:[!] <int>[,relative];<example>alert tcp any any -> any 111 (content:”PASS”; isdataat:50,relative; content:!”|0a|”; within:10;)111포트로 향하는 패킷에 “PASS” 문자열이 확인되면 50바이트 이후 시점에서 newline의 hex값(0a)을 찾는데 찾은 범위는 50바이트 떨어진 시점에서 10바이트 안에서 찾는다.
pcre
Perl 기반의 정규표현식을 사용할 수 있게 하는 옵션 이다.<형식>pcre:[!]”(/<regex>/|m<delim><regex><delim>)[ismxAEGRUBPHMCOIDKYS]”;
표 페이로드 탐지 옵션
페이로드에서 시그니처를 탐지하기 위해 사용하는 옵션 중 정교한 탐지 패턴을 구현하기 위해 사용하는 옵션이 pcre 옵션이다. content 항목은 단순 문자열 매치 기반이기 때문에 우회 공격이 발생되면 지정된 문자열로 탐지가 불가능해 질 수 있다. 그래서 이렇게 변화 가능한 상황을 가정해 탐지 유연성을 갖도록 pcre 옵션을 사용한다. 탐지 문자열은 정규표현식을 지원한다.
간편하게 파일 분석이 가능한 프로그램을 살펴 보자. 올리디버거를 이용한 파일 분석 방법은 책 한권 분량이 나올 만큼 양이 방대하다. 이미 올리디버거를 이용해 정적으로 악성코드나 파일을 분석하는 좋은 책들이 많이 있기 때문에 관련 내용을 참고하기 바랍니다.
침해사고분석 과정에서 악성코드로 의심되는 파일이 확보되면 해당 파일의 기능 분석을 수행한다. 수집된 악성코드를 별도의 분석 시스템으로 옮겨와서 분석할 수 있지만 경우에 따라서는 부득이 분석 대상 시스템에서 악성코드 분석을 수행하기도 한다. 시스템에 영향을 최소화 하고 악성코드로 의심되는 파일을 분석하는데 많이 사용되는 분석도구가 PEiD이다.
PEiD 프로그램은 정적으로 파일을 분석하는데 사용되고 실행파일의 API, 문자열 정보, 실행압축정보 등을 확인하는데 사용한다. 대표적인 기능과 함께 실제 PE헤더 파일을 분석해보자.
그림 PEiD
악성코드 샘플을 분석하는 것도 의미가 있지만 샘플을 구하기 어려운 경우 윈도우 시스템에 “cmd.exe” 파일을 분석해보는 것으로도 기능 파악에 도움이 된다.
분석할 PE파일을 불러 온다.
그림 PEiD 주요기능
문자열 검색
파일 디버깅을 통해서 파일에 포함된 식별 가능한 문자열 검색을 수행할 수 있다.
일부 악성코드의 경우 하드코딩 형식으로 마스터 서버에 접속할 IP정보를 PE파일안에 넣어 두기도 한다. 이 경우 악성코드가 어떤 IP로 접속하는지 혹은 어떤 프로그램인지 확인할 수 있다.
API 확인
실행 파일에서 사용되는 API를 통해서 대략적인 프로그램이 수행하는 행위에 대해 추측이 가능하다. 정확한 분석을 위해서는 디버깅 프로그램을 이용해 분석이 필요하겠지만, API를 확인하는 것으로 침해사고 분석에 필요한 정보를 확보할 수 있다.
그림 PEiD주요기능-API점검
PEiD는 현재는 업데이트가 중단되었다. 대체 도구는 아래 사이트를 참고해 필요한 목적에 맞게 사용할 수 있다.
효율적으로 침해사고 분석 업무를 수행하기 위해서 필요한 분석 도구를 살펴보자. 분석도구란 분석에 필요한 정보를 해석하고, 분석가가 쉽게 필요한 정보를 볼 수 있도록 도와주는 도구다. 이러한 분석 도구는 크게 네트워크 패킷 분석 도구와 로그 분석, 파일 분석 도구로 나눌 수 있다.
가장 많이 사용되는 와이어샤크에 대해서 살펴 보자. 예전 이더리얼이라 불렸던 와이어샤크는 무료로 사용할 수 있는 대표적인 패킷분석 프로그램 이다. 네트워크 트래픽 통계와 스트림 정보, 파일 추출 등 분석에 필요한 다양한 기능을 제공한다. 공격자에게 백도어가 있다면 분석가에겐 분석 도구가 있다.
와이어샤크는 분석가들 사이에 워낙 많이 사용되는 툴이기 때문에 기본적인 사용법은 홈페이지[1]를 참고하자. 우리는 분석할 때 유용한 메뉴를 중심으로 분석도구로서 사용하는 방법을 같이 살펴 볼 것이다. 그리고 간편하게 사용할 수 있는 네트워크마이너도 살펴볼 예정이다.
포렌식 관점에서 와이어샤크의 가장 유용한 기능은 패킷에서 파일을 추출하는 것이다. 먼저 파일을 추출할 pcap 파일을 불러온다. 파일을 불러오면 Export objects 명령을 이용해 파일을 추출하자.
File > Export objects
그림 와이어샤크(파일추출)
통신 프로토콜을 선택하다. HTTP 통신을 선택하면 다음과 같이 웹 통신을 통해 주고 받은 파일 목록이 나타난다.
그림 추출파일목록
Save All 명령을 이용해 전체 파일을 저장할 수 있고, 필요한 파일만 Save As 메뉴를 이용해 저장한다.
그림 추출파일저장
악성코드로 의심되는 파일을 추출하면 파일 분석 도구를 이용해 정적분석을 수행하거나, 가상머신에서 파일을 실행시켜 동적분석을 수행하는데 사용한다. 혹은, 기업이나 조직의 중요한 내부 문서가 외부로 유출되는 경우 의심 파일을 추출해서 증거로 사용한다.
트래픽 정보 확인
이상 트래픽을 분석하는 관점에서 와이어샤크가 제공하는 유용한 기능 중 하나는 저장된 pcap파일의 트래픽 정보를 통계적인 관점으로 제공하는 것이다. 와이어샤크에서 제공하는 메뉴 중에서 Statistic 메뉴를 활용하면 다양한 통계 정보를 확보할 수 있다.
Statistics -> IO 그래프
IO그래프를 분석에 활용하기 위해서는 필터링 항목을 적극 이용해야 한다. IO 그래프를 실행시킨 화면만으로는 이상 트래픽을 분석하기 위한 단서 정보를 찾기 어렵다. 아래 그림은 IO그래프를 실행 시킨 모습니다. 아래 그래프를 통해서 우리가 확보할 수 있는 단서는 12시 13분쯤 트래픽이 한차례 증가 되었고, 이후 12:14분에 다시 한번 트래픽 증가가 있었다는 내용이다.
그림 IO 그래프
좀더 분석을 효율적으로 하기 위해 우리는 각각의 프로토콜 별로 색깔을 다르게 그래프로 표시해 보자. 각각 프로토콜 별로 필터링을 통해 실제 의심 현상과 관련된 프로토콜 연관성을 확인하는 작업을 수행한다. 이러한 과정을 통해 많은 정보를 분석할 때 좀더 효율적으로 시간을 아낄 수 있다.
그림 IO 그래프그림 IO 그래프 패킷 필터 적용
Protocol Hierarchy
앞서 IO 그래프를 통해 전체 트래픽 중에서 이상 현상이 발생된 트래픽을 확인하는 과정을 수행 했다면, 실제 세부 트래픽을 분석하는 작업이 필요한데, 이때 statistic 메뉴 중에 프로토콜 하이라키를 이용하면 저장된 pcap 파일의 구조를 살펴 볼 수 있다. 전체 트래픽 중 패킷 비율이나 프토토콜 비율 확인을 통해서 분석의 단서를 찾아 나간다.
Statistics -> Protocol Hierarchy
그림 Protocol Hierarchy
패킷분석
효율적인 패킷 분석에 빠질 수 없는 것 중 하나가 패킷 필터이다. 기본적으로 표준 pcap 형식의 파일은 BPF(Berkeley Packet Filter)를 지원한다. 와이어샤크를 통해 불러온 pcap파일은 BPF 구문을 이용해 효율적으로 패킷 분석이 가능하다.
패킷 필터 구문 사용 시 기본 지원 되는 연산자 종류는 3가지가 있다.
연산자 종류
문법
AND 연산자
AND (&&)필터 구문간 AND 조합 연산샘플 구문 tcp.port == 80 && ip.addr == 74.195.238.237
OR 연산자
OR (||)필터 구문간 OR 연산샘플 구문 tcp.port == 80 || ip.addr == 74.195.238.237
NOT 연산자
NOT (!)지정 필터 구문에 대한 NOT 연산샘플 구문 tcp.port == 80 && !(ip.addr == 74.195.238.237)
필터 관련 문법은 와이어샤크 프로그램에서 자동완성 형식으로 저장되기 때문에 복잡한 구문을 일일이 외우고 있을 필요 없다. 필요한 프로토콜을 지정하면 사용 가능한 문법이 자동 완성 된다.
그림 패킷필터구문
네트워크마이너(NetworkMiner)
네트워크 패킷 분석 도구 중에 네트워크마이너에 대해서 살펴보자. 앞서 패킷 분석 작업에 가장 많이 사용되는 와이어샤크를 살펴 보았다. 와이어샤크를 사용하기 위해서는 프로토콜에 대한 이해도 필요하고 정보를 찾기 위해 프로그램에서 제공하는 메뉴에 대해 공부가 필요하다. 하지만 이번에 살펴볼 네트워크마이너는 쉽고 강력하게 분석가에게 필요한 정보를 제공하는 툴 중에 하나다. 저장된 pcap 파일을 프로그램에 불러오면 자판기에서 먹고 싶은 음료수를 누르듯이 필요한 정보를 클릭하기만 하면 된다.
프로그램을 실행하고 분석할 pcap파일을 오픈하면 자동으로 각각의 메뉴에 맞게 패킷을 가공 한다.
그림 네트워크마이너
분석가는 각 탭을 하나씩 클릭해서 분석에 필요한 정보를 하나씩 살펴 보면 된다. 복잡하게 필터 문법을 사용하거나 메뉴을 하나씩 클릭할 필요 없이 쉽게 필요한 정보를 마우스 클릭으로 찾아서 사용하면 된다. 어려운 툴을 사용해야만 고급 분석을 할 수 있는 건 아니다. 상황과 조건에 맞게 적합한 툴을 사용하는 것이 분석 도구를 선택하는 중요한 기준이다.
네트워크 기반의 패킷 분석 프로그램을 살펴 보았고, 이제 파일 기반의 분석 프로그램을 살펴보자.
전문 침해 대응 업무를 수행하기 위해서 필요한 기술의 종류는 다양하다. 트래픽 분석에서부터 악성코드 분석까지 보안 업무의 분야가 다양한 만큼 필요한 기술의 종류도 여러 가지다.
전문 침해 대응 업무를 수행하기 위해서 필요한 대표적인 업무 스킬 항목을 살펴 보자. 각 업무 마다 기술 수준에 따라 초급, 중급, 고급으로 나눌 수 있다. 기술수준을 나눌 때 어떤 기준으로 나누는지 표를 통해 살펴 볼 것이다. 해당 수준 정의는 조직이나 기업의 상황에 따라 차이가 발생할 수 있다.
패킷 분석 레벨
Beginner
단일 패킷 분석 – 처음 패킷을 분석하는 분석가는 개별 패킷을 구분하고 패킷 내용을 이해 합니다. 단편화된 패킷의 헤더와 페이로드 구성을 이해할 수 있습니다.
헤더 정보 이해 – 패킷 헤더에 포함된 프로토콜 정보를 이해 할 수 있습니다. TTL 의미와 IP Flags, Fragment Offset이 의미하는 내용을 이해할 수 있어야 합니다.
응용프로그램 식별 – 패킷 데이터의 페이로드 정보를 통해 통신 애플리케이션(응용프로그램)이 무엇인지 식별할 수 있어야 합니다. 식별을 위해 HTTP/FTP/SSH 등 응용 프로그램 프로토콜 통신 형식에 대해서 이해가 필요 합니다.
IP/Port정보 식별 – 클라이언트와 서버의 통신 주소와 통신 포트를 식별할 수 있습니다.
Intermediate
단일 패킷 분석 – 패킷을 분석하는 분석가는 개별 패킷을 구분하고 패킷 내용을 이해 합니다. 단편화된 패킷의 헤더와 페이로드 구성을 이해할 수 있습니다.
헤더 정보 이해 – 패킷 헤더에 포함된 프로토콜 정보를 이해 할 수 있습니다. TTL 의미와 IP Flags, Fragment Offset이 의미하는 내용을 이해할 수 있어야 합니다.
응용프로그램 식별 – 패킷 데이터의 페이로드 정보를 통해 통신 애플리케이션(응용프로그램)이 무엇인지 식별할 수 있어야 합니다. 식별을 위해 HTTP/FTP/SSH 등 응용 프로그램 프로토콜 통신 형식에 대해서 이해가 필요 합니다.
IP/Port정보 식별 – 클라이언트와 서버의 통신 주소와 통신 포트를 식별할 수 있습니다.
페이로드 분석 – 통신 애플리케이션 형식에 대한 이해를 바탕으로 전달된 파라미터 정보를 구분할 수 있습니다. 정상 파라미터 유형에 대해서 이해하고 있습니다. HTTP 통신에 사용되는 표준 통신 메소드 종류. Ex. GET / POST / HEAD 등
공격 패킷 구분 – 공격 관련 통신 애플리케이션과 비정상 통신 애플리케이션 특징을 구분할 수 있어야 합니다. 페이로드 분석을 통해 정상 통신 패킷의 파라미터 정보와 공격을 시도하는 패킷을 구분할 수 있어야 합니다.
공격 경로 식별 – 공격 패킷 페이로드에 포함된 정보를 분석해서 공격에 사용된 특징을 분석 할 수 있어야 합니다. HTTP URL 정보나 시스템 명령 실행 경로 등을 분석해서 공격이 발생한 대상과 위치를 식별할 수 있어야 합니다.
공격 영향 구분 – 공격 패킷 페이로드에 포함된 정보를 분석해서 공격에 사용된 특징을 분석 할 수 있어야 합니다. 파악된 공격 유형과 패킷에 포함된 시스템 응답 정보를 분석해서 공격이 성공했는지 실패했는지 파악 할 수 있어야 합니다. 파악한 정보를 통해 시스템에 발생 가능한 영향을 분석 할 수 있어야 합니다.
Advanced
단일 패킷 분석/ 풀패킷 분석 – 패킷을 분석하는 분석가는 개별 패킷을 구분하고 패킷 내용을 이해 합니다. 단편화된 패킷의 헤더와 페이로드 구성을 이해할 수 있습니다. 전체 패킷을 조합해서 세션 기반의 통신 정보를 분석 할 수 있어야 합니다. 공격자가 시스템에 연결한 시간, 시스템과 주고 받은 전체 데이터 양, 다운받거나 업로드한 파일 정보를 분석할 수 있어야 합니다.
패킷 재조합, 패킷 필터 – 키워드 또는 통신 유형에 따라 패킷을 재 구성하거나 방대한 패킷에 분석에 필요한 패킷을 효율적으로 분석 할 수 있습니다.
헤더 정보 이해 – 패킷 헤더에 포함된 프로토콜 정보를 이해 할 수 있습니다. TTL 의미와 IP Flags, Fragment Offset이 의미하는 내용을 이해할 수 있어야 합니다.
응용프로그램 식별 – 패킷 데이터의 페이로드 정보를 통해 통신 애플리케이션(응용프로그램)이 무엇인지 식별할 수 있어야 합니다. 식별을 위해 HTTP/FTP/SSH 등 응용 프로그램 프로토콜 통신 형식에 대해서 이해가 필요 합니다.
IP/Port정보 식별 – 클라이언트와 서버의 통신 주소와 통신 포트를 식별할 수 있습니다.
페이로드 분석 – 통신 애플리케이션 형식에 대한 이해를 바탕으로 전달된 파라미터 정보를 구분할 수 있습니다. 정상 파라미터 유형에 대해서 이해하고 있습니다. HTTP 통신에 사용되는 표준 통신 메소드 종류. Ex. GET / POST / HEAD 등
공격 패킷 구분 – 공격 관련 통신 애플리케이션과 정상 통신 애플리케이션 특징을 구분할 수 있어야 합니다. 페이로드 분석을 통해 정상 통신 패킷의 파라미터 정보와 공격을 시도하는 패킷을 구분할 수 있어야 합니다.
공격 경로 식별 – 공격 패킷 페이로드에 포함된 정보를 분석해서 공격에 사용된 특징을 분석 할 수 있어야 합니다. HTTP URL 정보나 시스템 명령 실행 경로 등을 분석해서 공격이 발생한 대상과 위치를 식별할 수 있어야 합니다.
공격 영향 구분 – 공격 패킷 페이로드에 포함된 정보를 분석해서 공격에 사용된 특징을 분석 할 수 있어야 합니다. 파악된 공격 유형과 패킷에 포함된 시스템 응답 정보를 분석해서 공격이 성공했는지 실패했는지 파악 할 수 있어야 합니다. 파악한 정보를 통해 시스템에 발생 가능한 영향을 분석 할 수 있어야 합니다.
이외에도 다양한 보안 관련 이벤트에 대해서 분석 가능한 역량이 구분 됩니다.
초급
중급
고급
패킷분석
단일 패킷 분석헤더 정보 이해응용프로그램 식별IP/Port정보 식별
단일 패킷 분석헤더 정보 이해응용프로그램 식별IP/Port정보 식별 페이로드 분석공격 패킷 구분공격 경로 식별공격 영향 구분
단일 패킷 분석/ 풀패킷 분석패킷 재조합, 패킷 필터헤더 정보 이해응용프로그램 식별IP/Port정보 식별 페이로드 분석공격 패킷 구분공격 경로 식별공격 영향 구분
로그분석
윈도우/유닉스 로그 타입 이해로그 저장 경로로그 내용 이해
윈도우/유닉스 로그 타입 이해로그 저장 경로로그 내용 이해비정상 로그 식별
윈도우/유닉스 로그 타입 이해로그 저장 경로로그 내용 이해비정상 로그 식별 트러블 슈팅원인 분석
네트워크침입탐지
IDS/IPS 이해오픈 소스(Snort)위험도 구분
IDS/IPS 이해침입탐지원리 이해오픈 소스(Snort)위험도 구분룰셋 이해기본 구성 및 설정
IDS/IPS 이해침입탐지원리 이해오픈 소스(Snort)위험도 구분룰셋 이해기본 구성 및 설정설정 최적화룰셋 제작네트워크 구성 및 설치
방화벽
방화벽 이해접근제어리스트(ACL)
방화벽 이해침입차단원리 이해접근제어리스트(ACL)ACL 작성
방화벽 이해침입차단원리 이해접근제어리스트(ACL)ACL 작성네트워크 구성 및 설치ACL 관련 고급 설정방화벽 운영 및 설정최적화
호스트기반침입탐지
HIDS 이해오픈 소스(OSSEC)
HIDS 이해침입탐지원리 이해오픈 소스(OSSEC)탐지 항목 이해룰셋 이해기본 구성 및 설정호스트 기반의 침입
HIDS 이해침입탐지원리 이해오픈 소스(OSSEC)탐지 항목 이해룰셋 이해기본 구성 및 설정호스트 기반의 침입HIDS 설치 및 구성 설계HIDS 탐지 및 수집 항목 정의
침입탐지시스템은 크게 2가지 형태의 탐지 방식을 갖고 있다. 시그니처 기반(misuse detection)과 행위기반이상(anomaly detection) 탐지 방식이다.
시그니처기반 이상탐지(misuse detection)
시그니처기반 이상탐지(misuse detection)은 침입탐지시스템 분석 엔진에서 패킷 정보를 수집하고 수집한 패킷에 대해 공격 시그니처 데이터베이스와 비교하여 공격 여부를 판단 한다. 이는 시그니처 데이터베이스에 존재하는 특정 패턴과 일치하는 경우 공격으로 판단하고 시그니처 데이터베이스에 있는 내용에 대해서만 공격 여부를 검증 한다. 다음이 흔히 웹 스캔을 시도했을 때 발생되는 URL요청의 일부로 이러한 URL요청을 데이터베이스에 저장하고 사용자의 요청에 해당 구문이 포함되는지를 확인해 공격성 여부를 판단하는 것이다.
장점 시그니처 기반 탐지라고 애기하는 Misuse detection은 특정 시그니처를 이용해 패킷에 포함된 데이터를 확인해 공격 여부를 판단 한다. 시그니처기반 이상탐지(misuse detection)에서 사용하는 시그니처는 공격과 관련된 특정한 행동, 변수, 인자값 등이 포합 된다. 시그니처 기반 탐지 방식은 다양한 이점이 있다. 그 중 한가지로 필드에 알려진 많은 수의 공격 행위가 시그니처로 작성 되었기 때문에 공격행위에 대해 다양하게 탐지가 가능하다. 공격 탐지 패턴을 이용해 쉽게 탐지할 공격 유형을 정의 하고 선택할 수 있다. 또한 시그니처 기반으로 탐지 시스템을 네트워크에 설치하면 별도의 학습과정 없이 바로 활성화 하여 탐지 및 방어를 할 수 있다. 마지막으로 탐지된 이벤트에 대해 쉽게 탐지 유형을 파악하여 적절한 행동을 취할 수 있다.
단점 다양한 이점만큼 다양한 문제점이 있다. 공격자의 공격행위에는 다수의 부가적인 행위가 포함 된다. 예를 들어 웹 공격을 시도하며사용하는 매개변수(특히 SQL Injection)가 사용자에 의해 변경될 경우 탐지 패턴이 없으면 탐지가 불가능해진다. 이처럼 시그니처를 이용해 공격 탐지 시 예측 가능한 변수를 포함하는데 한계가 있다. 또한 공격행위를 탐지 하기 위해서는 모든 행위에 대해 시그니처를 가지고 있어야 한다. 바꿔 말하면 시그니처가 존재하지 않는 공격 행위는 탐지가 불가능 하다는 의미가 된다. 이는 잦은 시그니처 업데이트가 필요함을 의미 하게된다. 공격자가 탐지를 우회할 목적으로 시그니처를 테스트 하고, 우회 가능한 공격 방식을 개발할 수도 있다.
행위기반 이상탐지(anomaly detection)
행위기반 이상탐지(anomaly detection)은 시스템 관리자가 특정한 사례 또는 환경에 대해 정상범위를 미리 정의 한다. 이는 트래픽이 될 수 있고, 웹 서버를 사용하는 사용자의 수가 될 수도 있다. 이 외에도 기준으로 사용 할 수 있는 항목으로 포트, IP, 프로토콜, 패킷 사이즈 등도 사용할 수 있다. 공격 또는 비정상을 구분하는 방법은 앞서 언급한 정상 범위, 즉 사전에 정의된 상황(프로파일)과 다른 상황이 발생되면 이를 비정상 상황으로 탐지 하는 방식 이다. 예로 평소에 웹서버에 접속하는 사용자가 오후 1시에 3만~4만명 사이라고 가정해 보자. 어느날 오후 1시에 웹서버에 접속하는 사용자 수가 1000명으로 줄어 들거나 10만명으로 갑자기 늘어날 경우 침입탐지시스템에서 이를 통보 하게 되는 것이다
그림 비정상상황탐지
행위 기반 이상탐지 방식의 장점과 단점을 살펴보자.
장점
행위기반 이상탐지(anomaly detection) 방식을 사용하기 위해서는 앞서 언급 한데로 먼저 정상 상황에 대한 정의(프로파일)가 필요 하다. 정상이라고 정의한 상황을 기준으로 변칙적인 상황이 발생될 경우 비정상 상황으로 판단 한다.
시스템에 사용자가 추가 또는 삭제 되는 경우 바로 행동 기반 방식에 의해 탐지가 가능 할 수 있다. 이는 일반적으로 사용자가 추가/삭제가 자주 발생하지 않는다는 가정하에서 사용자가 추가 또는 삭제되는 정상 행위에 대해 하나의 비정상 상황으로 가정하고 탐지할 수 있다는 의미다. 두번째로 각각 개별 환경에 따라 기준 또는 정상으로 정의한 상황이 틀리기 때문에 공격을 시도하는 입장에서는 탐지를 우회할 방법을 찾기가 매우 어렵다. 시그니처 기반의, 예를 들면 스노트룰의 경우 웹 상에 탐지 패턴이 공개되어 있기 때문에 언제든지 패턴을 획득하여 우회할 방법을 찾을 수 있지만 사용자 또는 시스템관리자가 정의한 개별 상황은 추측을 통해 우회 방법을 찾기가 매우 어렵다.
단점
대부분의 침입탐지시스템에서 행위기반 이상탐지(anomaly detection) 시스템은 몇 가지 문제를 갖게 된다. 먼저 비정상 상황에 대한 구분을 위해서는 반드시 적절한 기준이나 프로파일을 가지고 있어야 탐지가 가능하다는 점이다. 만약 기준 상황을 정의하는 기간 동안 공격이 발생되어 해당 기준 상황에 공격 행위가 포함될 경우 이 또한 정상 상황으로 판단될 수 있다. 이보다 큰 문제는 시스템의 복잡성과 임계치 설정이 매우 어렵다는 것이다. 만약 공격 행위나 상황이 정상 상황에 너무 가까워서 탐지가 되지 않을 수도 있고, 반대로 정상 사용자를 공격자로 탐지할 수도 있다.
이상탐지 기법을 기반으로 네트워크 또는 호스트의 보안 위협을 분석 한다. 침입분석대상의 사이버 보안 위협을 분석하는 방식을 살펴보자.
침입분석대상
앞서 침입탐지시스템에서 공격 행위를 변별하기 사용하는 2가지 방식을 살펴 보았다. 이번에는 이러한 탐지 방식을 적용하는 계층에 대해 살펴 보기로 하자.
공격 시도를 네트워크상에서 탐지 할 것인지 더 하위 레벨인 시스템에서 탐지 할 것인지에 대한 결정이다. 이 두가지 초점에 따라 탐지 매커니즘을 적용하는 대상에 차이가 발생 한다. 네크워크상에서 송/수신 되는 패킷의 데이터를 분석해 공격을 판단할 것인지, 시스템의 프로세스를 분석해 공격을 판단할 것인지 목적에 따라 차이가 발생 한다.
네트워크 감시(병목 감시)
일반 적으로 네트워크 환경을 구성할 때 웹 서버 및 서비스에 사용할 시스템을 IDC에 설치 하게 된다. 설치된 서버의 경우 동일 IP대역을 할당 받아 특정 범위의 서브넷 범위 안에서 네트워크 환경을 구성 한다. 병목 감시는 동일한 서브넷에 전달되는 모든 패킷에 대해 공격 여부를 탐지 하는 방식으로, 병목 처러 패킷이 집중되는 지점에서 서버로 전달되는 모든 패킷을 분석하고 공격 시도를 분별하는 방식이다.
이 때 사용되는 방법이 미러링 방식과 인라인 방식이 있는데 이는 네트워크 상에 침입탐지 시스템을 어떤 식으로 구성하는 냐를 일커는 용어이다. 스위치 장비나 기타 네트워크 장비에서 전체 트래픽을 침입탐지시스템으로 미러링하여 패킷을 검사 하거나 인라인 모드로 침입탐지시스템을 설치해 감시 하는 방식 이다. 이 구성에 대해 구체적인 형태는 뒤쪽 탐지 구성에서 다시한번 살펴 보기로 하자. 이처럼 네트워크상에서 네트워크 패킷을 감시하는 시스템을 Network Intrusion Detection System(NIDS)라 한다. 네트워크 기반의 침입탐지 시스템(NIDS)과 호스트 기반의 침입탐지 시스템(HIDS)의 가장 큰 차이가 바로 감시 대상의 차이인데, 앞서 설명한 미러링, 인라인 방식으로 네트워크 병목에서 공격 트래픽을 감시하는 것이 NIDS이다. HIDS와의 구분은 감시하는 트래픽이 단일 시스템인지 아니면 전체 네트워크 트래픽인지 차이이다. NIDS는 모든 네트워크 패킷을 검사하고, HIDS는 오로지 특정 호스트에 수신되는 트래픽만을 검사한다. 그럼 단일 호스트를 대상으로 트래픽을 감시하는 HIDS에 대해 살펴보자.
호스트 감시
앞서 NIDS와 HIDS의 차이에 대해 간단하게 언급 하였다. HIDS는 패킷 분석 외에도 침입시도를 탐지 하기 위해 다양한 방법으로 시스템을 감시 한다. 호스트 단위로 감시할 경우 다양한 시스템에서 발생되는 정보까지 활용할 수 있는 장정이 있다. 가장 많이 연동해 분석하는 정보를 다음과 같다.
감시항목
설명
Log Parsing
시스템에 저장되는 로그는 공격 시도를 확인 할 수 있는 좋은 소스 중 하나다. 많은 침입탐지시스템이 시스템 로그를 연동해 공격 행위가 탐지 되면 경고를 발생 시킨다. 일부 공격의 경우 시스템 로그에 공격 로그를 남기기 때문에 로그를 통해 공격을 감지 할 수 있다. 다음은 호스트 단위의 침입탐지시스템의 공격 탐지 로그다. sshd[3698]: fatal: Local: crc32 compensation attack: network attack detected
System Call Monitoring
호스트 기반의 침입탐지시스템은 운영체제의 커널모니터를 통해 잠재적으로 위험한 프로그램의 시스템 콜을 감시 할 수 있다. HIDS에서는 요청된 시스템 콜이 비정상으로 판단되면 경고를 발생 시키거나 호출된 시스템 콜을 막는 방식으로 침입시도를 찾아내고 차단한다.
Filesystem Watching
또 다른 기능은 중요한 파일의 사이즈를 감시하고 있다가 변환가 생기면 경고를 발생 시키는 방식이다. 중요한 시스템 파일이나 바이너리 파일의 크기가 변경될 경우 조작된 바이너리 파일로 교체된 것일 수 있기 때문에 경고를 발생 시키는 것이다. 파일 시스템 감시 방식를 이용해 웹 서버에서는 웹 경로의 파일 변조가 발생되는지 감시하여 웹 페이지가 위조 되거나 변조 되는 것을 탐지 한다.
탐지구성
네트워크 침입탐지 시스템은 네트워크 구성에 따라 미러링 방식과 인라인 방식으로 구성 한다. 먼저 미러링 구성은 원 암드(one armed) 방식이라고도 하는데 한쪽으로 팔을 뻗은 것처럼 복사된 패킷을 탐지 분석 한다. 스위치의 각 포트에 흐르는 트래픽을 특정 포트로 복사해 패킷을 미러 시켜 패킷을 검사 한다. 인라인 방식은 라우터와 스위치 사이(구성에 따라 위치는 바뀔 수 있다.)에 침입탐지시스템을 설치 한다. 인라인 방식은 침입차단장비 구성 시 많이 사용 된다. 인라인 구성 시 공격 패킷은 침입차단장비에서 차단 하거나 강제로 리셋 패킷을 전달하여 침입 시도한 공격자의 통신을 차단한다.
그림 미러링 방식과 인라인 방식 탐지
침입탐지 시스템 탐지우회 방법
공격 행위를 탐지 하기 위해 다양한 기법과 알고리즘이 사용되듯이 탐지를 피하기 위해서도 많은 기법이 끊임 없이 사용 된다. 해킹을 시도하는 공격자는 침입탐지시스템에서 탐지되는 것을 피하기 위해 다양한 방법으로 우회를 시도 한다. 많은 우회 기법이 있지만 예제로 우회기법과 관련해서 이중 디코딩을 통한 탐지 우회 방법과 패킷 프레그먼트 2가지 방법에 대해 살펴 보자
침입탐지시스템에서 탐지를 우회하기 위해 악성코드 제작자는 쉘 코드 작성 시 인코딩하여 작성 한다. 인코딩 한 코드의 경우 디코드 과정을 거쳐 패킷 분석이 필요하다. 소개할 사례는 인코딩된 소스 코드 중 악의적인 목적의 공격 코드에 자주 포함되는 NOP코드를 인코딩하여 우회 시도하는 방법에 대해 살펴보고 디코딩하는 방법을 살펴 보자.
NOP (no-operation) 코드 인코딩
90 NOP
90 NOP
Exploit 코드 제작자는 작성한 쉘 코드가 실행될 정확한 메모리 상의 위치를 추정하기 어렵다. 이는 각은 운영체제에서 사용하는 프로그램이나 설치된 패키지에 따라 정확한 주소값이 달라지기 때문이다. 오버 플로우 또는 언더플로우 등의 공격을 통해 시스템 처리 루틴의 주소 값을 조작하는 단계에 성공했다고 해도, 최종 목적지인 공격자가 작성한 프로그램 코드, 즉 쉘코드가 실행 되는 지점으로 돌아와야 한다. 그렇기 때문에 일정 부분 쉘 코드 앞에 여유 공간을 확보해 리턴 주소가 공격자가 작성한 쉘 코드를 지나치지 않도록 Exploit 코드를 제작한다.
이 때 쉘 코드 앞의 일정 부분을 NOP코드(0x90)로 채워 여유 공간을 확보 한다. 리턴값이 NOP코드를 만나면 아무것도 수행하지 않고 지나쳐 공격자가 작성한 쉘 코드에 이르게 되어 코드가 실행 된다. 많은 Exploit 코드에 NOP코드가 포함되는데 침입탐지시스템에서는 과도한 NOP코드 사용을 exploit코드로 탐지 한다. 탐지를 우회하기 위해 코드 제작자는 여러 가지 방법으로 NOP코드를 인코딩 하고, 침입탐지시스템에서는 이를 탐지 하기 위해 디코딩기법을 적용하거나 인코딩한 데이터를 탐지 패턴으로 사용하게 된다. 인코딩 기법으로 자주 사용되는 몇 가지 방식을 살펴보자.
엔티티 인코딩 방식 예제를 보자. 앞서 NOP코드는 16진수 값으로 0x9090, 10진수 37008 이다. 해당 값을 엔티티 인코딩 방식으로 다음과 같이 인코딩 할 수 있다.
“邐” or “邐”
프레그먼트(Fragment)
스노트 기반의 침입탐지 시스템의 특징이 패킷을 기반으로 특정 문자열이나 헤더값을 검사 하기 때문에 조각난 패킷(fragmented)의 경우 데이터에 포함된 공격 구문을 바로 찾기 어려울 수 있다. 이러한 이유로 스노트 엔진에서는 전처리기라는(preprocessor) 모듈을 통해 조각난 패킷을 재조합 하는 과정을 거치게 된다. 물론 성능의 한계로 무한 재조합은 현실적으로 불가능하다.
이러한 조각난 패킷은 탐지 시스템의 서비스 거부 공격에도 사용되기도 한다. 아주 작게 패킷을 조각내 공격 대상 시스템에 전송하여 패킷을 수신한 시스템에서 재조합에 많은 리소스가 사용되게 만들어 리소스를 고갈 시키는 방식이다. 그러면 대상 시스템은 패킷 조합에 리소스를 과도하게 사용하여 서비스 제공이 불가능한 상태가 된다.
서비스 거부 공격 외에 탐지 우회하기 위한 방법으로도 사용된다.
대부분 네트워크 기반 침입탐지 장비가 병목에 설치된다. 침입탐지시스템 엔진은 네트워크에서 캡쳐한 패킷의 공격성 여부를 판단하고 액션을 취한다. 하지만 침입탐지시스템이 탐지한 모든 패킷이 대상 호스트로 도달하지 않을 수도 있다. 각각의 단편화된 패킷은 각각 TTL설정에 의해서 도착지 IP까지 도착하지 못하고 네트워크에서 유실 될 수도 있다. 침입탐지 시스템을 우회하기 위해 공격 패킷을 조각 내고, 각각의 패킷의 TTL을 다르게 설정해 호스트까지 도착하는 패킷을 선택할 수 있다.
9개의 조각난 패킷을 침입탐지 시스템에서 재조합해 “cmdo.bexe”라는 구문을 탐지 했다고 가정 하자. 탐지한 “cmdo.bexe” 구문이 공격성이 없는 것으로 판단하고 패킷을 처리했으나, 호스트에서는 9개 중 2개를 뺀 7개의 패킷을 수신하였다. 수신된 패킷은 조합 결과 “cmd.exe” 구문이 포함되어 시스템 명령이 실행 되었다.
프레그먼트 패킷번호
공격구문
목적시스템 도달여부
1
C
수신
2
M
수신
3
D
수신
4
O
미수신
5
.
수신
6
B
미수신
7
E
수신
8
X
수신
9
E
수신
표 패킷 수신/미수신
공격자는 “cmd.exe”를 실행하기 위해 중간에 눈가림으로 사용할 ‘o’와 ‘b’가 포함된 패킷을 보내야 했다. 하지만 목적지 호스트에 모든 패킷이 도착했을 때는 ‘o’와 ‘b’가 포함되면 안됐다. 그래서 공격자는 TTL값을 다르게 설정해 필요 없는 패킷을 서버에 도착하기 전에 없앴다. 목적지 호스트에 도착하는 패킷의 TTL값보다 작은 값을 설정해 패킷을 중간에 사라지게 한것이다.
이를 타켓 베이스(Target-based) 공격 방식이라 얘기 한다.
시스템 전체 전송 단위(Maximum Transmission Unit)
통신 과정에 프레그먼트되지 않고 전송되는 패킷의 사이즈는 제한이 있다. 이는 패킷을 제각각 사이즈로 생성하여 생기는 통신 장애를 방지하기 위해 사전에 프레그먼트되지 않고 전송되는 퍄킷 사이즈를 정한 것이다.
물론 일부 개발과정에서 사이즈를 넘는 패킷을 만들어 사용하기도 한다. 동영상 데이터의 경우 패킷 사이즈를 초과하는 경우가 자주 발생하는데 이로 인해 일부 네트워크 장비나 통신 장비에서는 비정상 패킷으로 처리하여 통신이 끊기거나 지연되는 경우가 종종 발생 하곤 한다.
다음은 프로토콜 별 MTU 설정에 대한 자료다.
형식
시스템 전체 전송 단위 (바이트)
Internet IPv4 Path MTU
At least 576[1]
Internet IPv6 Path MTU
At least 1280[2]
Ethernet v2
1500[3]
Ethernet (802.3)
1492[3]
Ethernet Jumbo Frames
1500-9000
802.11
2272[4]
802.5
4464
FDDI
4500[3]
표 프로토콜 별 시스템 전체 전송 단위
코드를 인코딩하거나, 조각 내어 침입탐지시스템이나 기타 탐지에 대해 우회하는 시도에 대해 살펴 보았다. 물론 탐지를 우회하는 기법은 매우 다양하다. 언급한 2가지 방식은 이 중 일부이다. 침입탐지 시스템에서는 혹은 여러분은 공격자에 의한 공격이 정상 또는 어렵게 보이는 데이터로 가장하고 들어 올 수 있다는 것을 침입시도를 확인할 때 항상 유념해야 한다. 자, 이제 네트워크에서 이뤄지는 해킹 시도를 탐지하기 위해 네트워크 상의 어떤 위치에서 침입탐지 시스템이 운영되고 어떤 트래픽을 감시 하는지 살펴보자.
기업이나 정부 기관에서는 침해사고가 발생하면 사전에 정의된 업무 절차에 따라 사고대응 활동을 수행한다. 금융권 혹은 개인정보 유출과 연관된 사고의 경우에는 기업 내부뿐만 아니라 관리 기관과 함께 사고 조사를 수행하기도 한다. 침해사고 대응 활동을 통해 사고 원인을 파악하고 피해가 재발하지 않도록 재발방지 방안을 수립하는 것이 침해사고대응 활동의 목적인다. 침해사고 대응 하는 과정을 요약 하면 다음과 같다.
표 침해사고분석 과정 요약
사고의 유형은 다양하다. 랜섬웨어에 의해 시스템의 중요한 데이터가 암호화되는 피해를 입거나, 사전식 대입 공격을 통해서 시스템에 공격자가 침입할 수 있다. 사고 유형에 따라 침해사고를 어떻게 분석할지 분석가는 조사 방법을 정의 한다. 증거 수집 과정은 침해사고원인을 파악하기 위해 필요한 정보를 모으는 과정이다. 사전식 대입 공격에 의해서 사고가 의심되는 경우에는 침해사고원인 분석을 위해서 시스템의 로그인 로그가 필요하다. 만약 랜섬웨어에 의해 파일이 암호화 되었다면 시스템 명령 실행내역과 프로그램 설치 내역이 사고원인 분석을 위해 필요하다. 사고 원인을 정확히 파악하기 위해서는 공격자의 흔적이 기록된 정보를 활용한다. 증거 수집 과정에서는 다양한 보안 솔루션이 활용된다. 엔드포인트에서 수집된 로그에서 부터 클라우드 기반의 로그까지 다양한 로그를 활용한다. SOC팀에서 운영하는 보안 솔루션 장비가 분석가가 사고 조사 시 수집 대상으로 고려가 필요한 로그 정보다. 다음 그림은 SOC 보안 모니터링을 위한 솔루션 아키텍처 그림이다.
그림 – SOC 솔루션 아키텍처
수집된 로그를 가공하고 분석에 필요한 정보만 추출하는 과정을 거쳐 침해사고와 핵심이 되는 정보를 분석하게 된다. 최근에는 다양한 보안 솔루션을 이용해서 상관분석을 수행한다. 서로 다른 보안 장비간에 연관된 사고 관련 이벤트를 그래프나 히트맵으로 시각화해 분석 시간을 효율적으로 활용할 수 있게 도와 준다. 머신러닝(Machine Learning)을 활용해 방대한 로그를 분석해 사고와 관련된 이벤트를 사전에 탐지 할 수 있는 방법도 다양하게 시도된다. 보안 위협 탐지와 분석 과정에 인공지능 기술이 활용되면 업무 효율성을 높일 수 있을 것으로 기대 된다. 침해사고 원인이 확인되면 재발방지를 위해 필요한 조치를 정의 하고, 개인정보가 유출되거나 기업 고객 정보와 관련된 피해가 발생했다면 관련 규정에 따라 필요한 조치가 포함된 의사 결정이 이뤄진다. 일련의 침해사고분석 과정이 정상적으로 완료되면 침해사고 케이스를 종료한다.